
Your model got smarter.
But suddenly it got slower.
Why does increasing context length explode compute?
Because attention is O(n²).
And that becomes the real bottleneck in modern LLMs.
Your model got smarter. But suddenly it got slower. Why does increasing context length explode...
Your model got smarter.
But suddenly it got slower.
Why does increasing context length explode compute?
Because attention is O(n²).
And that becomes the real bottleneck in modern LLMs.

As AI agents take on longer tasks, the KV cache of LLMs has become a massive bottleneck. Discover how sparse attention techniques…

Learn why more tokens hurt LLM reasoning, where low-signal noise comes from, and how reranking, hybrid search, and semantic…
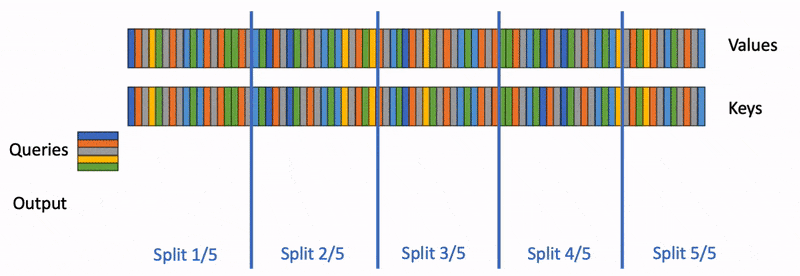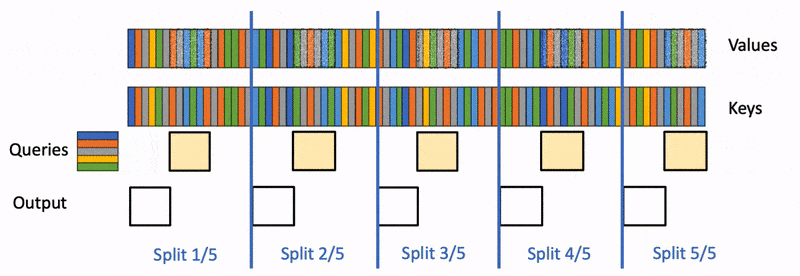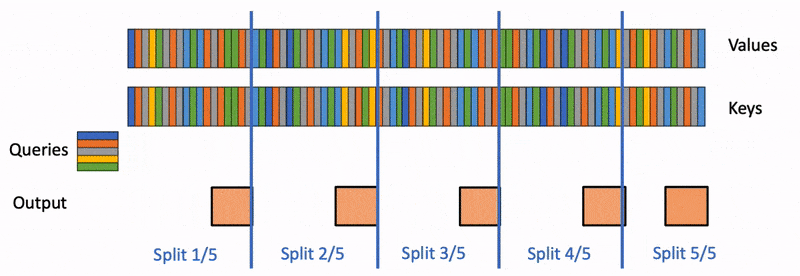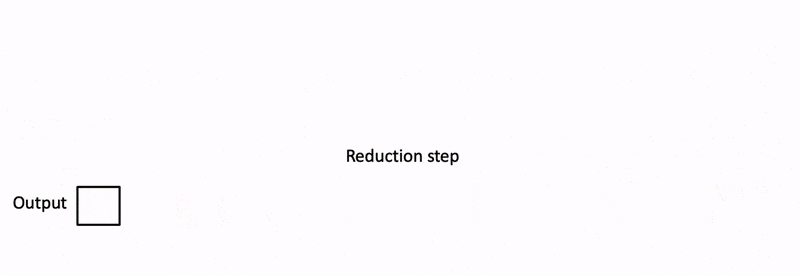
Large language models (LLM) such as ChatGPT or Llama have received unprecedented attention lately. However, they remain massively…

Memory Sparse Attention (MSA) scales LLM context windows to an unprecedented 100 million tokens while preserving accuracy.

A Blog post by poe on Hugging Face

This article was originally published on GetYourDozAi. * Key Takeaways MiniMax M3 — the...