Back to Articles
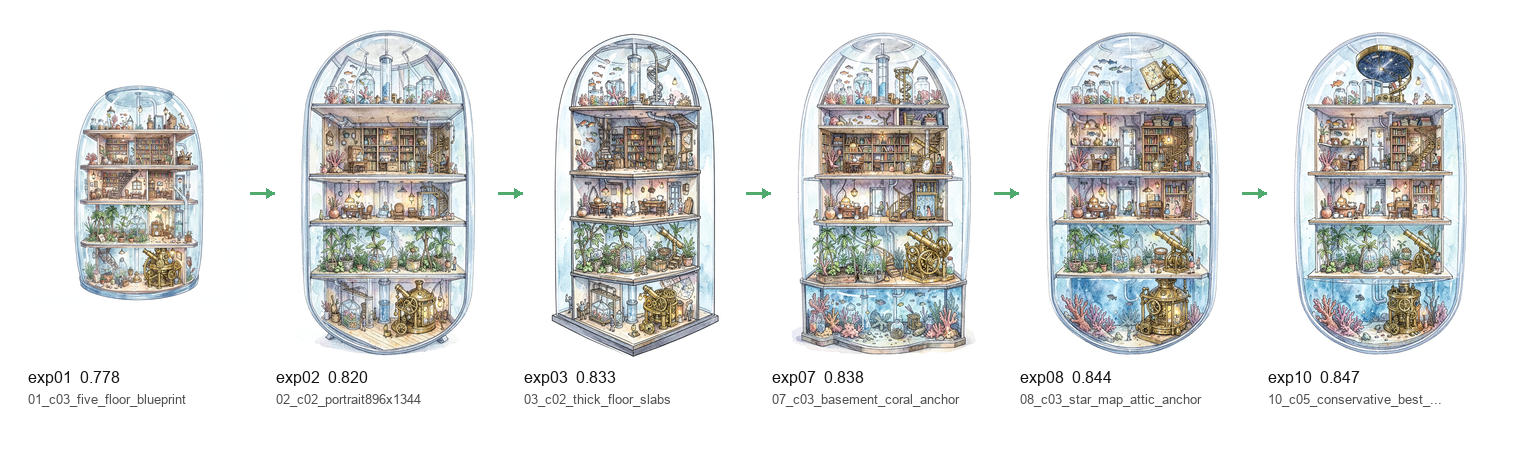
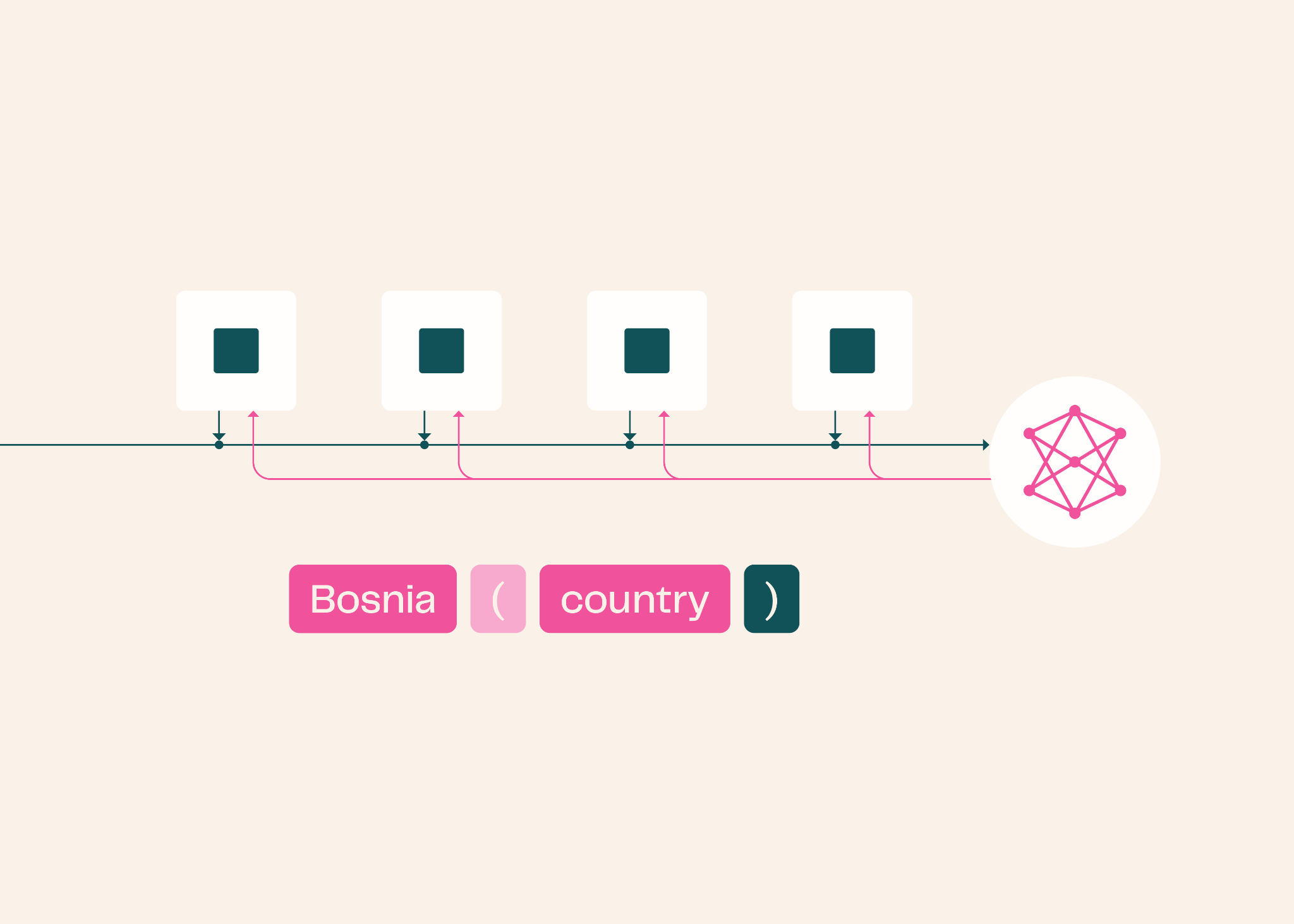
The setup What I measured Results What this means Why this experiment still matters My takeaway Closing thought What tools I used At first I asked myself:
is it possible to replace full attention with something cheaper, while still keeping enough context to generate the right next token?
can a model preserve weak, parallel instructions without explicitly classifying them?
if we compress context into a smaller state, what do we actually lose?