Back to Articles
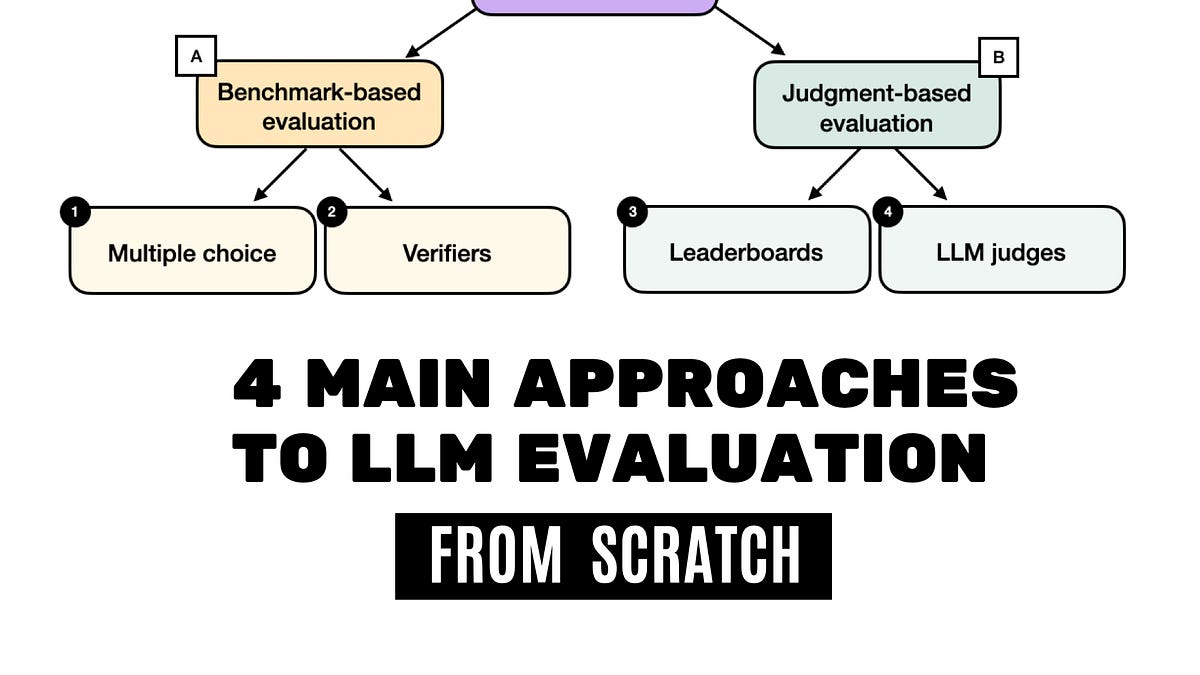
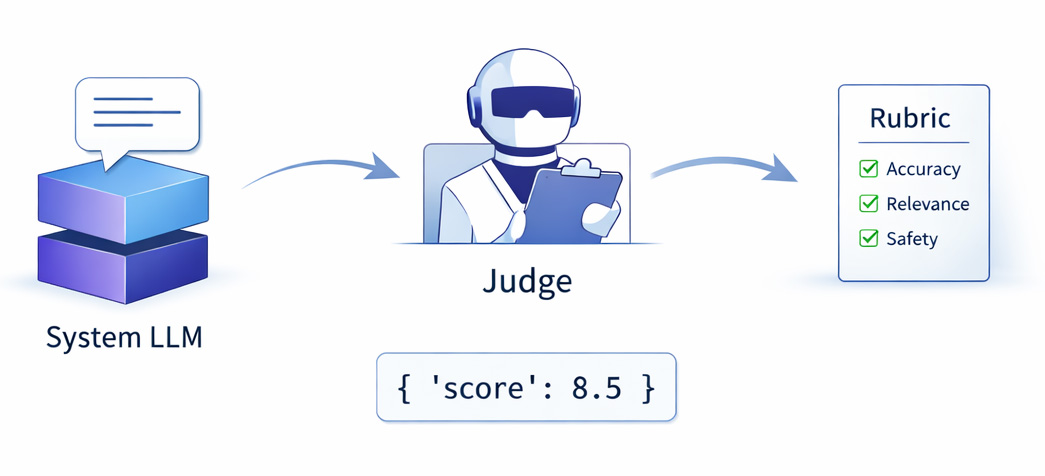
How do we do LLM evaluation? Benchmarks Human as a judge Model as a judge Why do we do LLM evaluation? 1) Is my model training well? Is my training method sound? - Non-regression testing 2) Which model is the best? Is my model better than your model? - Leaderboards and rankings 3) Where are we, as a field, in terms of model capabilities? Can my model do X? Conclusion Acknowledgements Since my team works on evaluation and leaderboards at Hugging Face, at ICLR 2024 (2 weeks ago) a lot of people wanted to pick my brain about the topic (which was very unexpected, thanks a lot to all who were interested).
Thanks to all these discussions, I realized that a number of things that I take for granted evaluation wise are 1) not widely spread ideas 2) apparently interesting.
So let's share the conversation more broadly!
How do we do LLM evaluation?