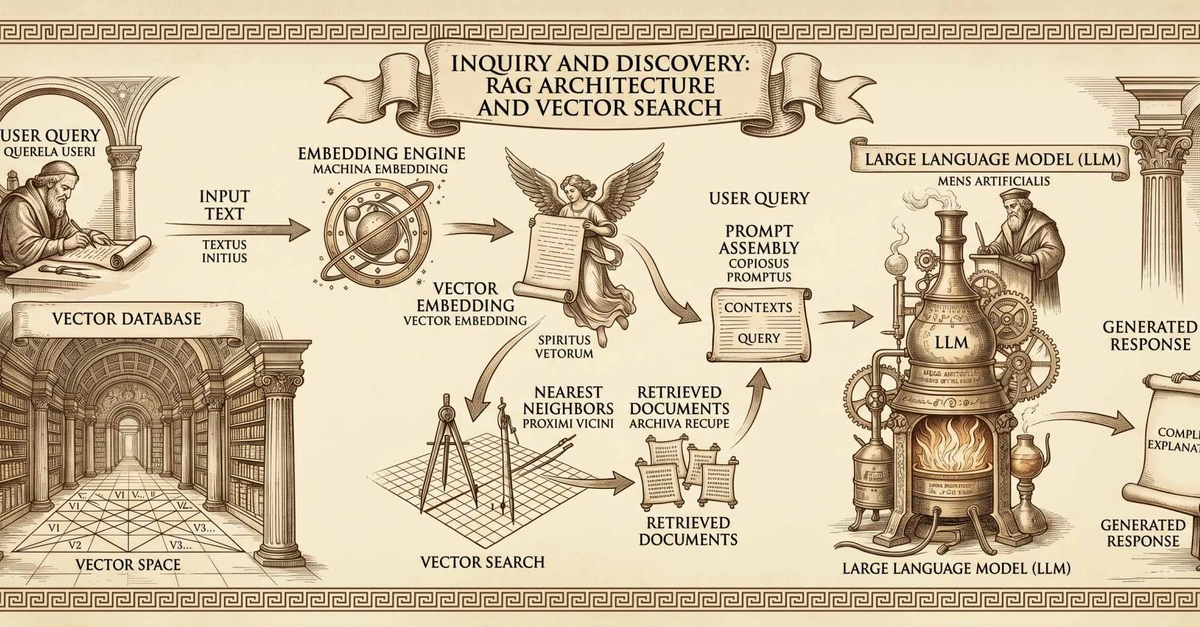
A short learning path from a weekend project: I indexed my personal markdown notes (~800 chunks), tried a few local embedding models, stored the same vectors in four different backends, and wired up simple RAG. Not a production guide — just the basics, with honest results from a corpus small enough to reason about.
The idea, without the jargon pile
Keyword search looks for shared words. Vector search converts text into a list of numbers (an embedding), treats that list as a point in space, and finds nearby points. Similar meaning → nearby, even when the words differ.
That is the retrieval half of RAG (Retrieval-Augmented Generation):
your docs → split into chunks → embed → store in a vector index





