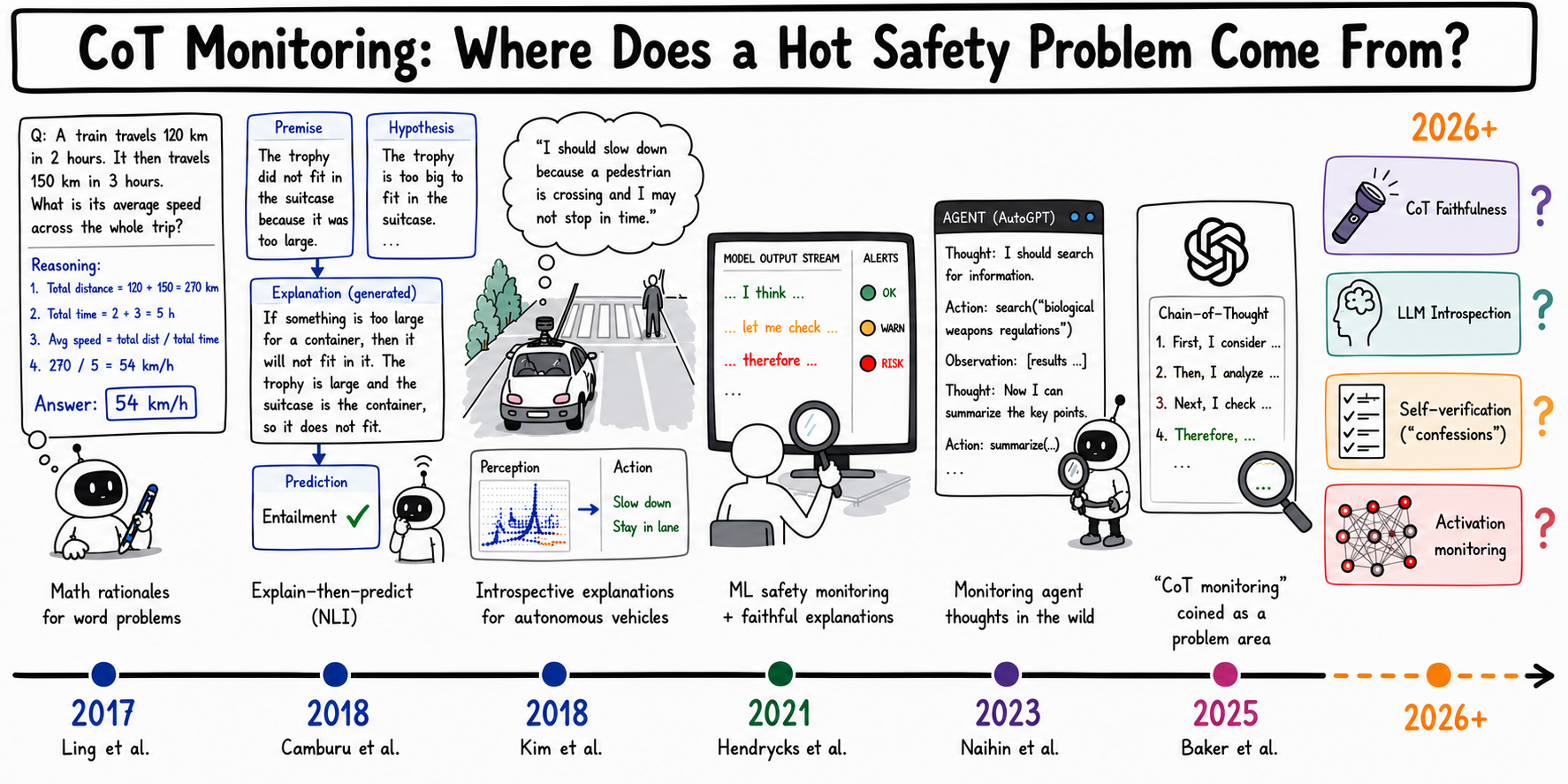
Chain-of-thought monitoring hit production this year, almost exactly twelve months after the term “CoT monitoring” first appeared on arXiv (Baker et al., 2025). This technique involves using an automated monitoring system, such as a prompted LLM, to flag another model’s output as potentially unsafe based on the contents of that model’s chain-of-thought reasoning. Alongside industrial deployments of this technique, an active research domain has sprung up.
Where did this hot problem in AI safety come from? And how did it appear in a state of such apparent maturity? It is not normally the case that an agenda paper with 41 authors appears four months after the very first mention of the topic area (“CoT monitoring”) on arXiv. Usually many-author agenda papers like this are written in an attempt to course-correct years of slow progress, not fresh on the heels of the first “methods” paper in an area.
A timeline of research ideas in the history of CoT monitoring.
We suspect that, as with many concepts in AI safety, this one finds its origins in informal conversations among researchers and technologists (in this case probably concentrated in the SF Bay Area and London). These conversations might be directly or indirectly inspired by the literature or they may arise independently. We may never know the true story. When an idea is in the air, though, it can be because it has been slowly diffusing through the intelligentsia of AI. This means that the proximate explanation for the agenda paper may well be that some researchers ended up chatting about it together. However, it is still valuable to track how the idea emerged in the literature.