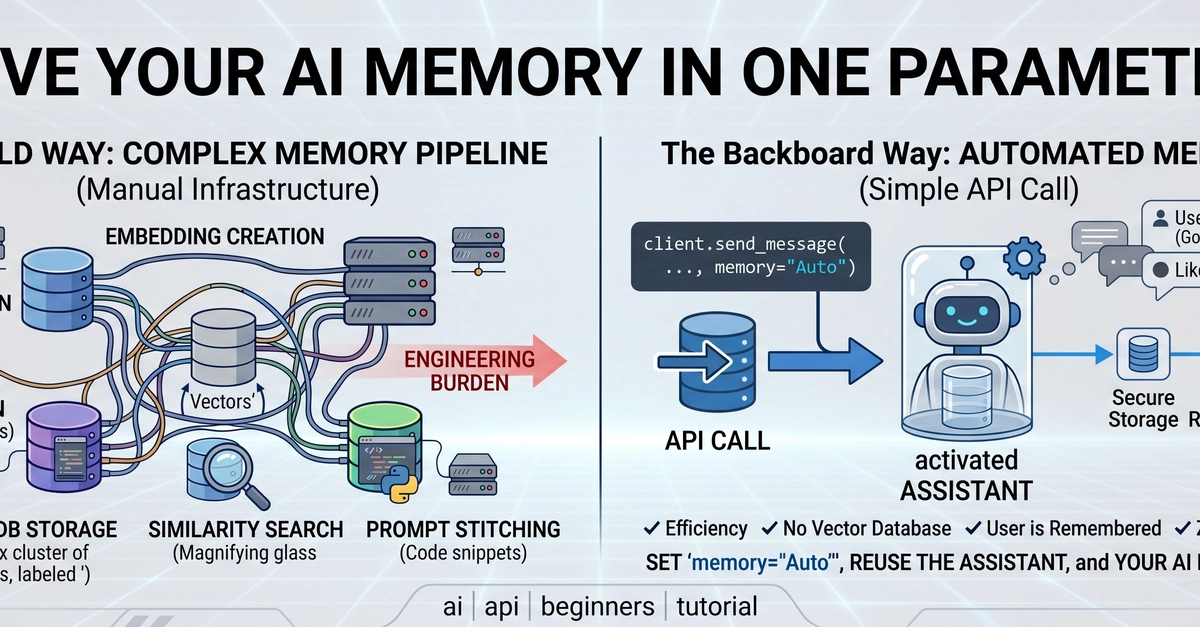
Introduction
Before I dug into how an LLM works, I assumed each chat stored its memory or context in its own. The moment I realized it was just an array with all the messages appended gave me a sense of control. I wish I had known this sooner. This is invisible in a chat session; Claude and OpenAI pull a lot of threads to pull up a context accurate response. To know about those threads first, I needed to work with an LLM API with raw fetch, no SDK, and understand the request/response cycle.
Digging in
We want to build strong fundamentals, so not using the Anthropic SDK frees us from abstractions we may not notice. The SDK provides idiomatic interfaces, type safety, and built-in support for streaming, retries, and error handling. Without the SDK, nothing is abstracted away. Every decision is visible, which is exactly the point.
Normally, with the SDK to call the API, you'd need to add a script like this one: