Every new chat with your LLM starts the same way. Hi, here's the context. Here's the stack. Here's what we tried last week. Here's the constraint nobody wrote down. By the time the model is caught up, you've burned ten minutes paying for ground you already covered.
Then you close the tab and it forgets all of it.
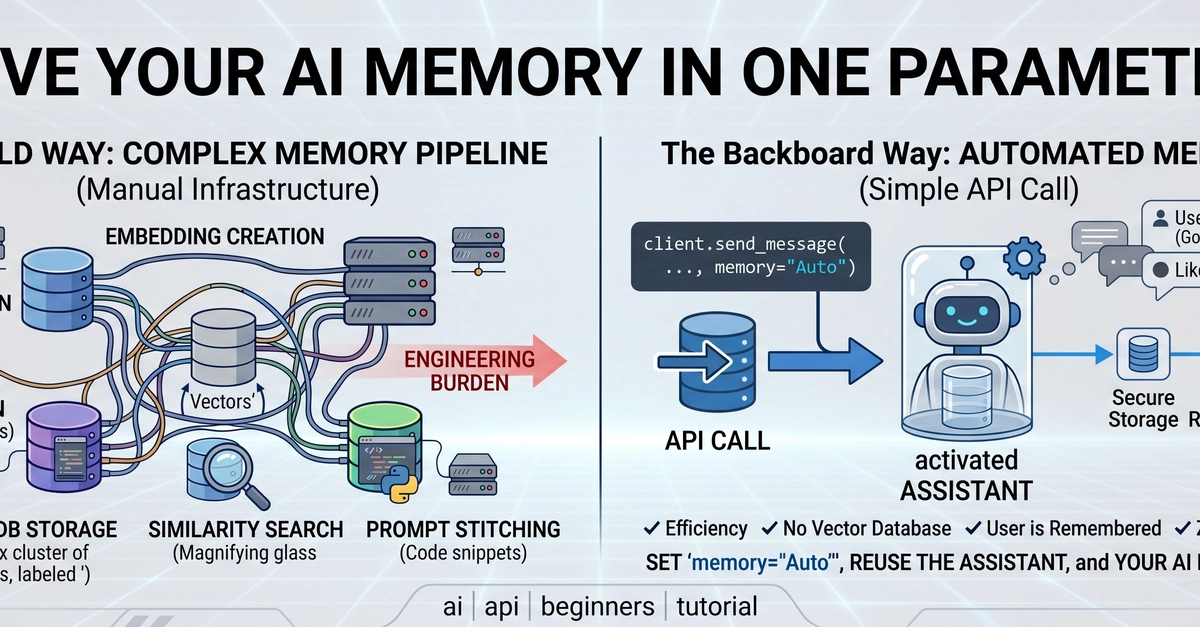
This is the part of "AI workflows" nobody really solved. Context windows got bigger. Agent frameworks got smarter. MCPs sprouted everywhere. The model still wakes up amnesiac every morning.
Bigger context windows are not memory
People keep treating context length as a memory solution. It isn't. A 1M-token window means you can paste more into one conversation — not that anything carries over to the next one. The moment the chat ends, or compaction kicks in, you're back at zero.