A trace of a hybrid Mamba-Transformer MoE inference run, broken down by layer type. The MoE all-to-all collective stalls dominate the tail. The dashboards saw 96% GPU utilization the entire window.
TL;DR
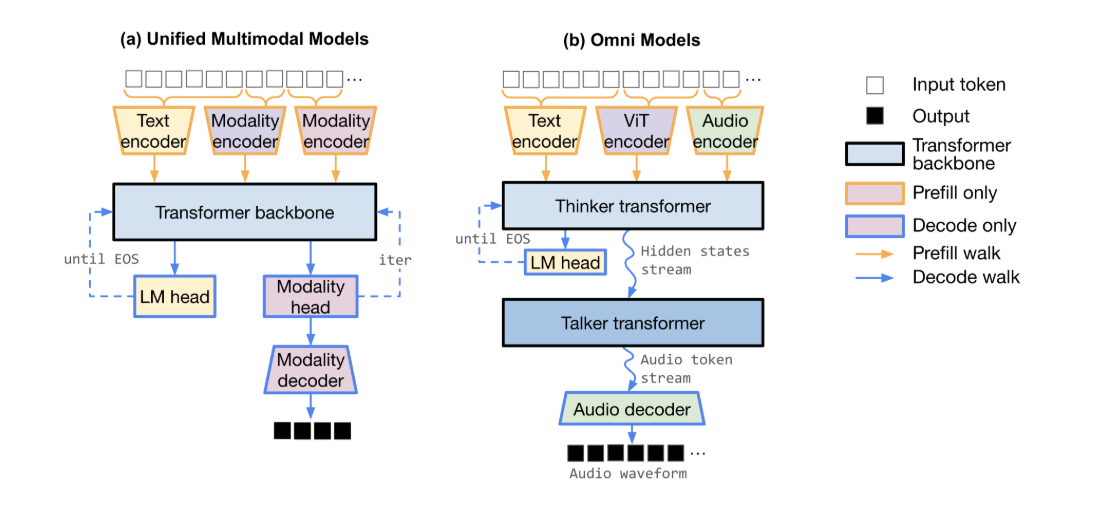
Hybrid Mamba-Transformer architectures (Nemotron 3 Nano Omni, Jamba and friends) shipped at speed in late April. These models break the assumptions vLLM and SGLang dashboards make about prefill/decode shape: Mamba state-space layers have one runtime profile, Transformer attention has another, MoE router blocks have a third (with all-to-all collective comm). The aggregate looks fine on a duty-cycle counter; the per-layer tail is full of hybrid MoE stalls nobody is decomposing. We trace one and decompose it.
What changed in late April
NVIDIA Nemotron 3 Nano Omni (Apr 28, open multimodal MoE) is the most prominent recent shipment, but it is one of several. The shape is consistent: a hybrid Mamba-Transformer backbone with mixture-of-experts routing, tuned to claim higher throughput than pure-Transformer baselines at comparable parameter counts.