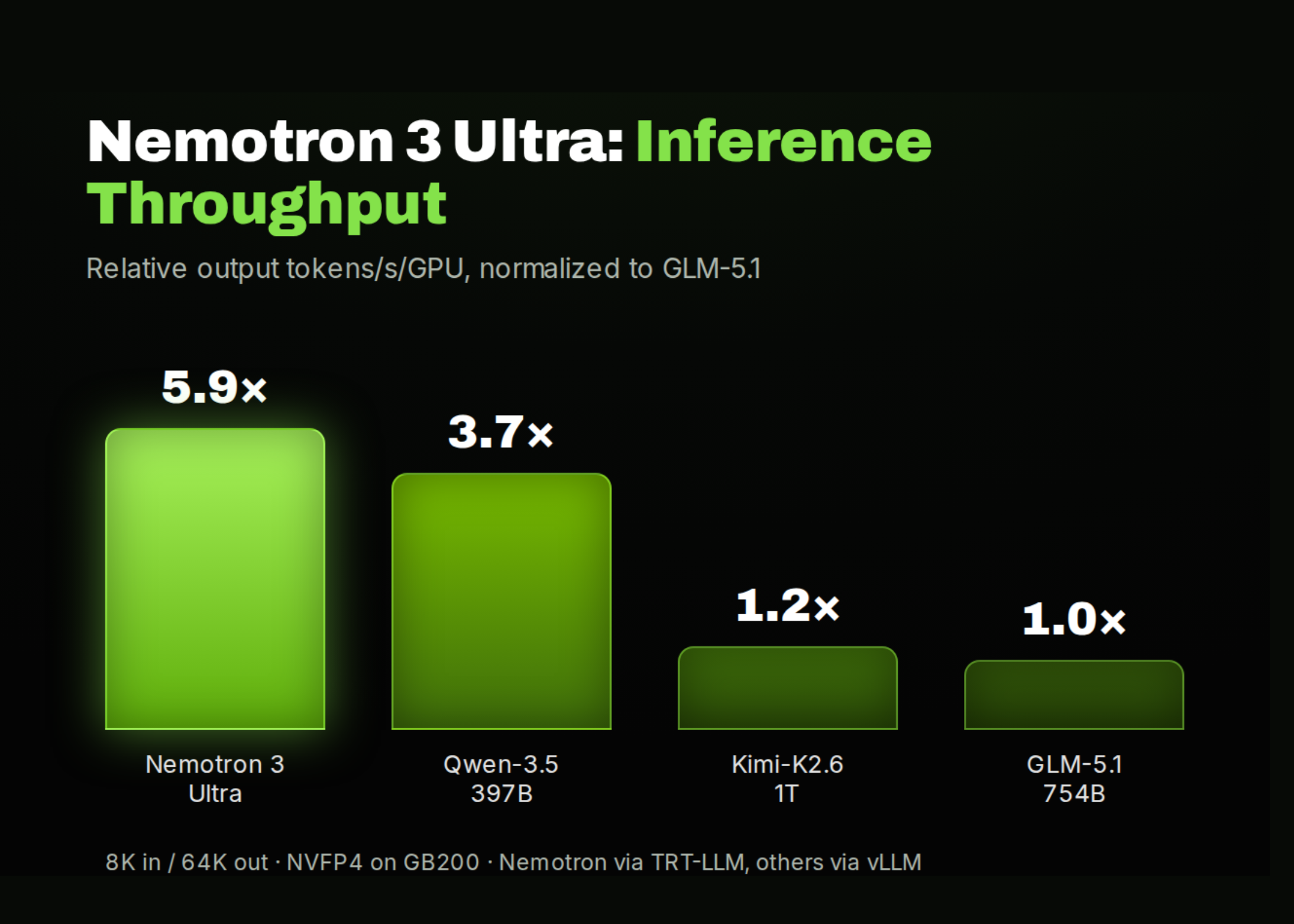
NVIDIA has released Nemotron 3 Ultra, the largest model in its Nemotron 3 family. It targets a specific problem: long-running agents that plan, call tools, and reason across many turns. As agents run longer, token counts grow and inference cost climbs. Nemotron 3 Ultra is designed to keep accuracy high while making that inference faster and cheaper.
What is Nemotron 3 Ultra
Nemotron 3 Ultra is a 550 billion total parameter Mixture-of-Experts (MoE) model. Only 55 billion parameters are active per token. The MoE design improves accuracy per active parameter.
It uses a hybrid Mamba-Attention architecture instead of a pure Transformer. Mamba layers handle long sequences with sub-quadratic scaling. A few Attention layers are kept for precise recall over large contexts.
The model was pre-trained on 20 trillion text tokens. Context was then extended to 1 million tokens. It was post-trained using Supervised Fine-Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD).












