HomeAI · summaries
Storia in 5 fonti
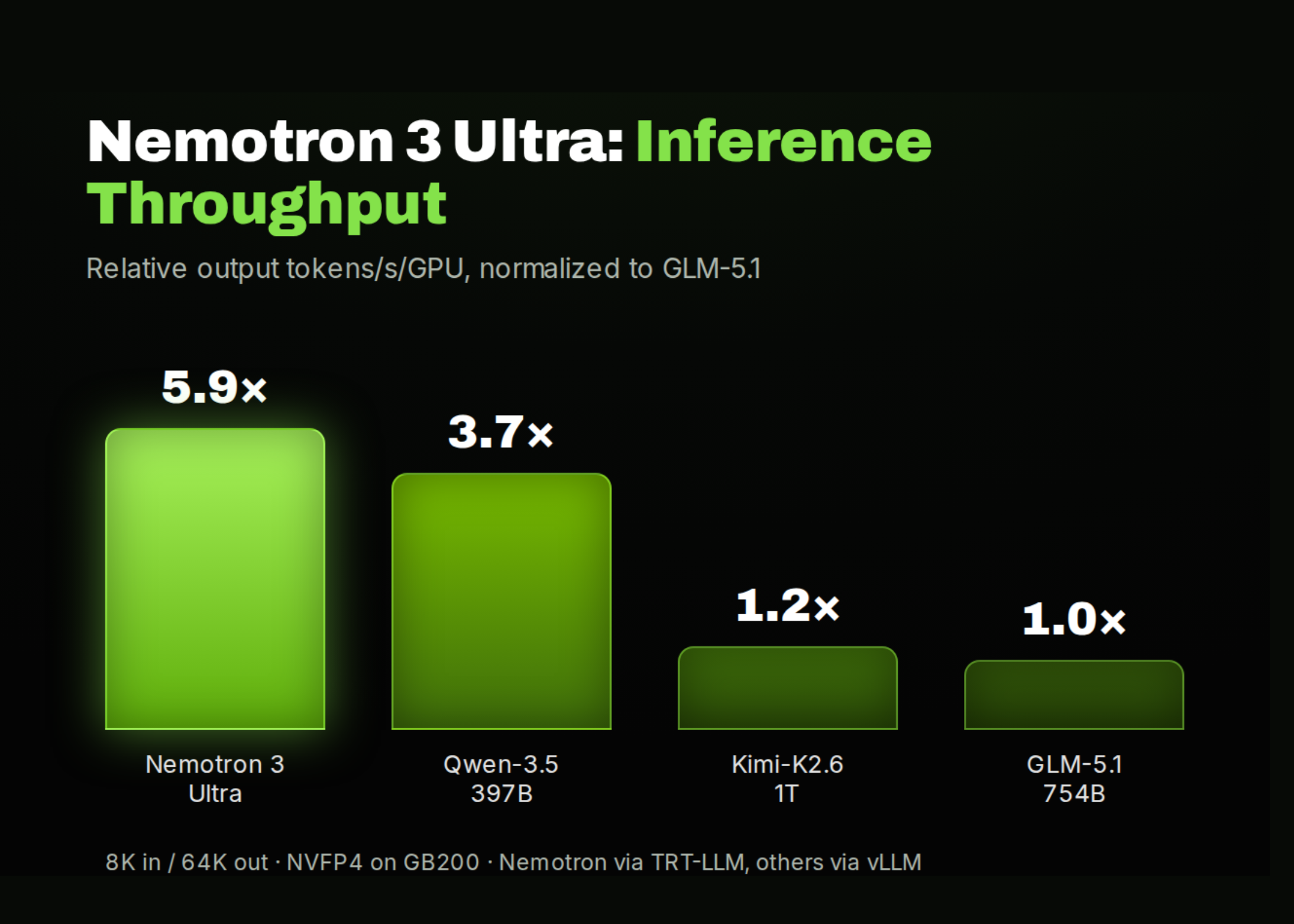
NVIDIA AI Releases Nemotron 3 Ultra: An Open 550B Mixture-of-Experts Hybrid Mamba-Transformer for Long-Running Agents
NVIDIA has released Nemotron 3 Ultra, a 550B total (55B active) open Mixture-of-Experts hybrid Mamba-Transformer for long-running agents. It pairs a 1M-token context with up to ~6x higher inference throughput than comparable open LLMs at on-par accuracy, and ships with open weights, training data, and recipes under OpenMDW-1.1.
Confronto fonti
5 prospettive sulla stessa storiaTimeline cronologica
- ·
dev.to

NVIDIA Nemotron 3 Ultra 550B: Developer Guide — Architecture, Benchmarks & Deployment
NVIDIA unveiled Nemotron 3 Ultra at Computex 2026: 550B MoE model, 55B active, 1M token context, 300+ tok/s, 48 AA Intelligence Index. Complete developer deploy
- ·
morningstar.com

AibleClaw Now Powered by NVIDIA Nemotron 3 Ultra Delivers Frontier-Class Planning for Claws and Enables Stronger Post-Training of Smaller…
Enterprises can now leverage AibleClaw to securely and cost effectively run long-running AI agents or claws with NVIDIA Nemotron 3 Ultra for frontier-class planning and use its…
- ·
developer.nvidia.com

NVIDIA Nemotron 3 Ultra Powers Faster, More Efficient Reasoning for Long-Running Agents | NVIDIA Technical Blog
Single-turn chatbots are evolving into long-running agents that can reason, maintain context, use tools, and run efficiently across many turns to complete complex workflows.…
- ·
aws.amazon.com

NVIDIA Nemotron 3 Ultra now available on Amazon SageMaker JumpStart | Amazon Web Services
Deploy NVIDIA Nemotron 3 Ultra on Amazon SageMaker JumpStart. Get 5x faster inference and 30% lower cost for agentic AI workloads with this frontier reasoning model.
- ·
marktechpost.com
NVIDIA AI Releases Nemotron 3 Ultra: An Open 550B Mixture-of-Experts Hybrid Mamba-Transformer for Long-Running Agents
NVIDIA has released Nemotron 3 Ultra, a 550B total (55B active) open Mixture-of-Experts hybrid Mamba-Transformer for long-running agents. It pairs a 1M-token context with up to…
- ·

NVIDIA Releases Nemotron 3.5 ASR: A 600M-Parameter Cache-Aware Streaming Model Transcribing 40 Language-Locales in Real Time
NVIDIA Nemotron 3.5 ASR is an open-weights 600M streaming speech model transcribing 40 language-locales with configurable latency.