Jensen Huang walked on stage at Computex 2026 in Taipei on June 1 and announced what NVIDIA calls the most intelligent open-weights AI model built in the United States: Nemotron 3 Ultra, a 550-billion-parameter mixture-of-experts model that delivers over 300 output tokens per second and cuts complex agentic task costs by 30 percent. The weights ship to Hugging Face on June 4, 2026. Here is everything developers need to understand the architecture, run the benchmarks, and deploy it.
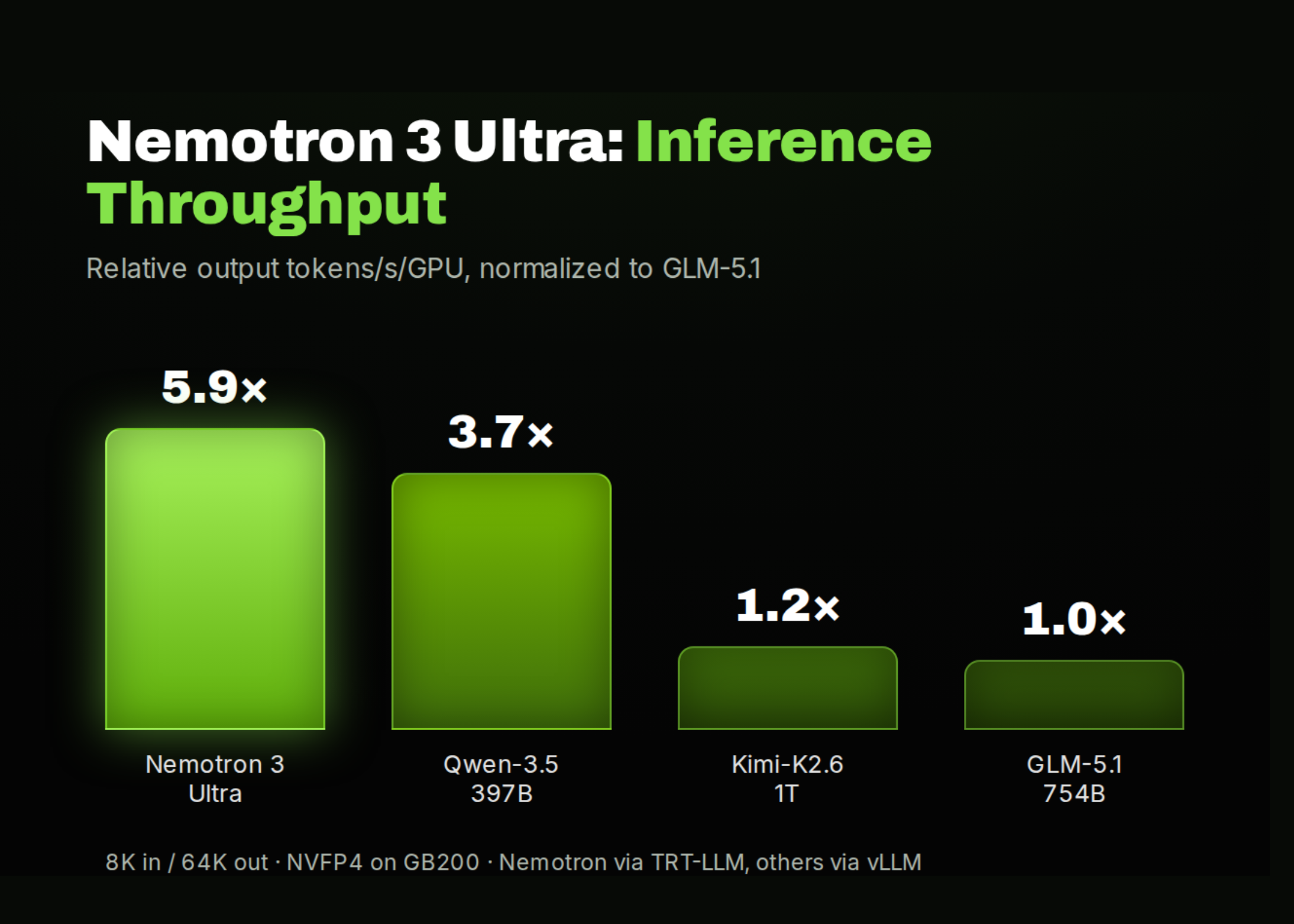
The announcement lands at a significant inflection point. The two models currently at the top of the frontier — Claude Opus 4.8 and GPT-5.5 — are proprietary, API-only, and priced accordingly. DeepSeek V4 Pro, the only open-weights competitor anywhere near frontier performance, requires roughly 862GB of VRAM to run — effectively a dedicated GPU cluster. Nemotron 3 Ultra is NVIDIA's answer to both constraints: intelligence approaching the frontier, open weights, and an architecture engineered for throughput rather than just accuracy.
The Numbers: What You Are Actually Getting
The headline specs: 550B total parameters, 55B active per forward pass via mixture-of-experts routing, a 1-million-token context window, and native support for multi-token prediction. The model was trained in 4-bit NVFP4 precision on NVIDIA's Blackwell architecture — the same hardware on which it runs most efficiently in production.