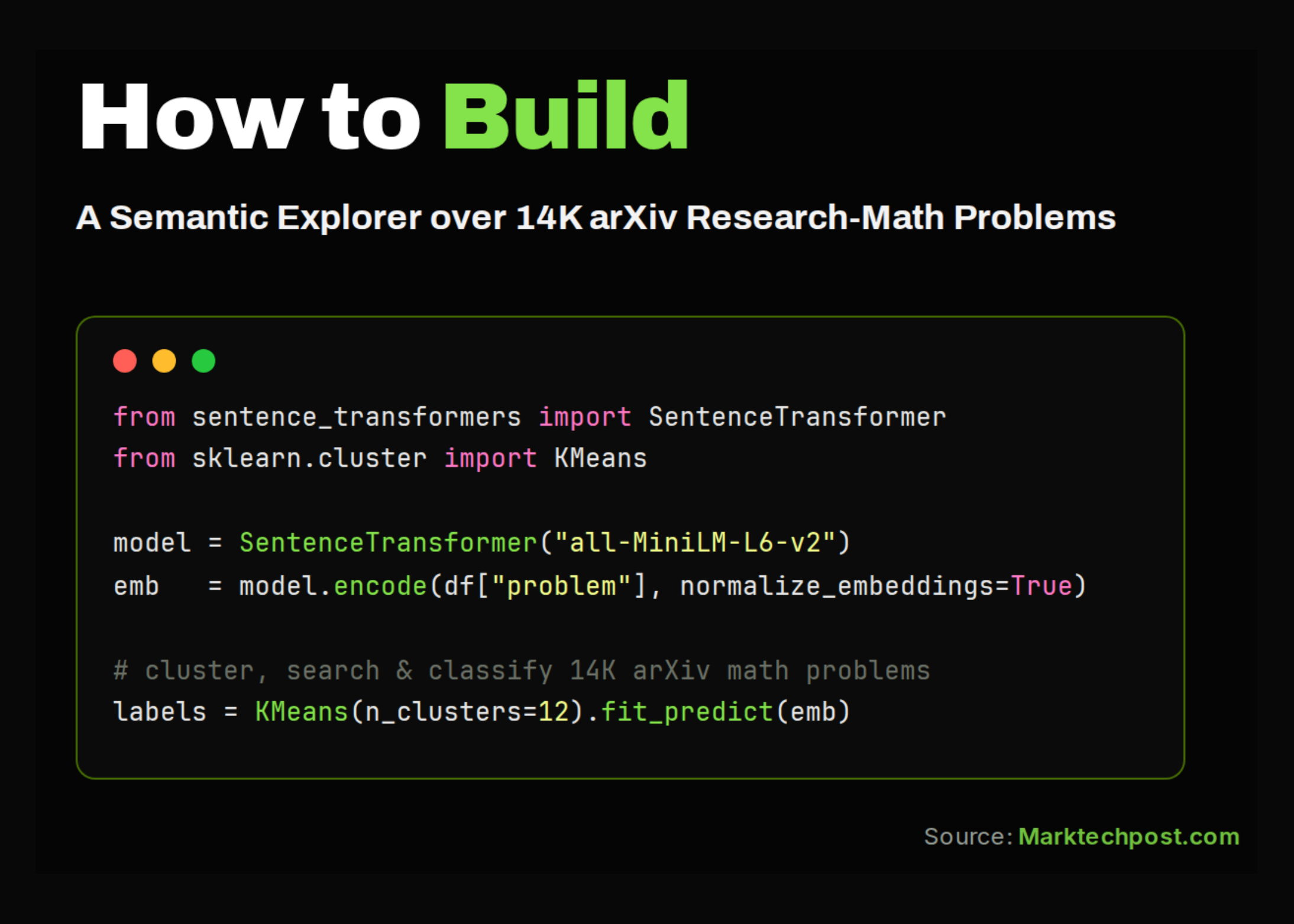
In this tutorial, we explore the FineWeb dataset through an advanced hands-on workflow. We stream a manageable sample of the dataset without downloading the full multi-terabyte corpus, inspect its schema and metadata, and analyze key fields such as URL, language, language score, and token count. We also reproduce simplified versions of FineWeb’s quality-filtering pipeline, apply MinHash-based near-duplicate detection, verify token counts with the GPT-2 tokenizer, and generate useful analytics on domains, language scores, document lengths, and tokenizer efficiency.
import subprocess, sys
def pip(*pkgs):
subprocess.run([sys.executable, "-m", "pip", "install", "-q", *pkgs], check=True)
pip("datasets>=2.19", "datasketch", "tiktoken", "pandas", "matplotlib", "tqdm")