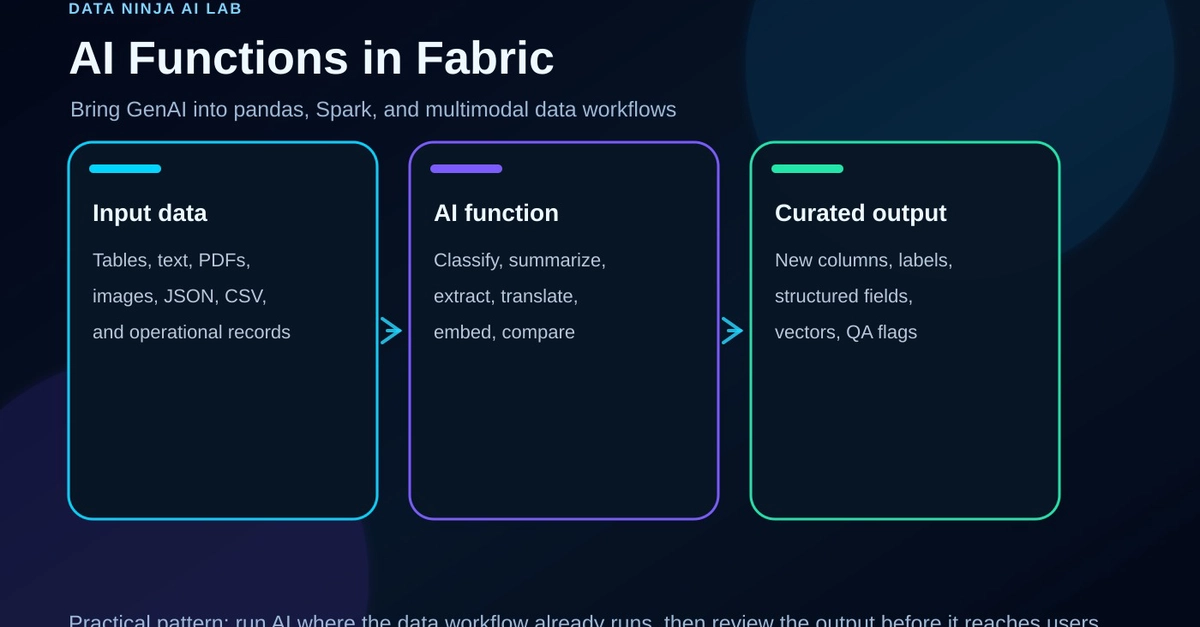
In the previous article, I extended a small Python data quality ETL starter with AI-ready data preparation.
The important constraint was that the workflow did not call an LLM API, generate embeddings, or train a model. It prepared structured data assets such as schema profiles, data dictionaries, validation summaries, feature-ready CSV files, and manifest files.
Previous article:
Preparing AI-Ready Data Without Calling an LLM API
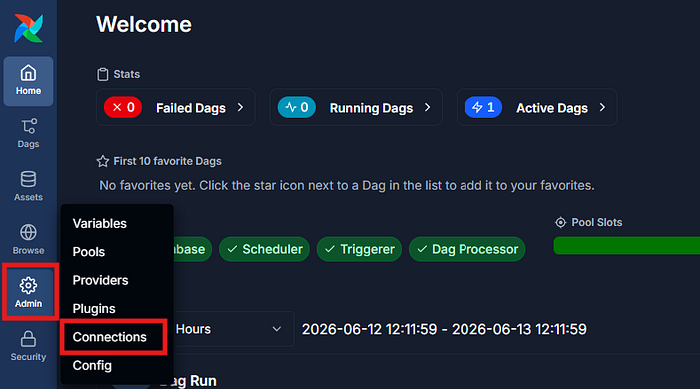
This follow-up focuses on the v0.7.0 update of the same project: