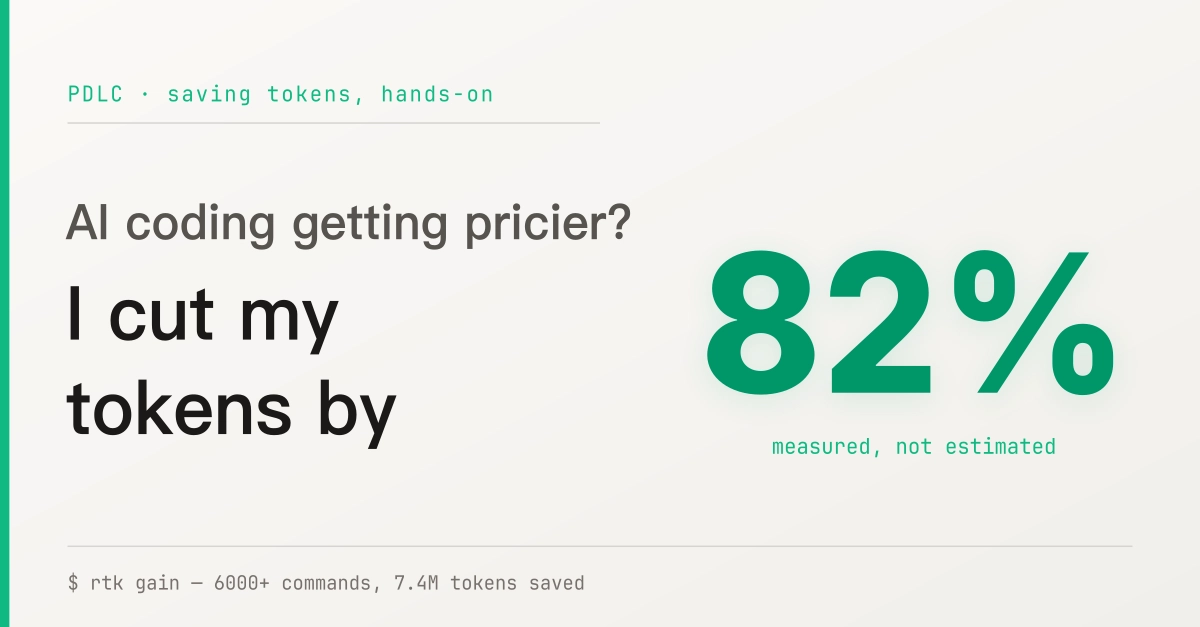
I cut a coding agent's input tokens by 71% — from 5.07M down to 1.46M across a 66-task run — and quality stayed within model noise (63 vs 64 of 66 tasks solved).
This post is the benchmark, the failures, the honesty caveats, and the code. No "revolutionary." Just numbers you can reproduce.
TL;DR
What it is: tokdiet — a local streaming reverse proxy that sits between your agent tools (Claude Code, Cursor, Codex, custom scripts) and the model APIs (Anthropic, OpenAI, Gemini, MiniMax, anything OpenAI/Anthropic-compatible).
The headline number: input tokens 5.07M → 1.46M = -71%; quality 63/66 vs 64/66 baseline ≈ parity. 198 paired runs. LLM-judge reports 92% similarity. Confirmed on a 2nd model at -72%.