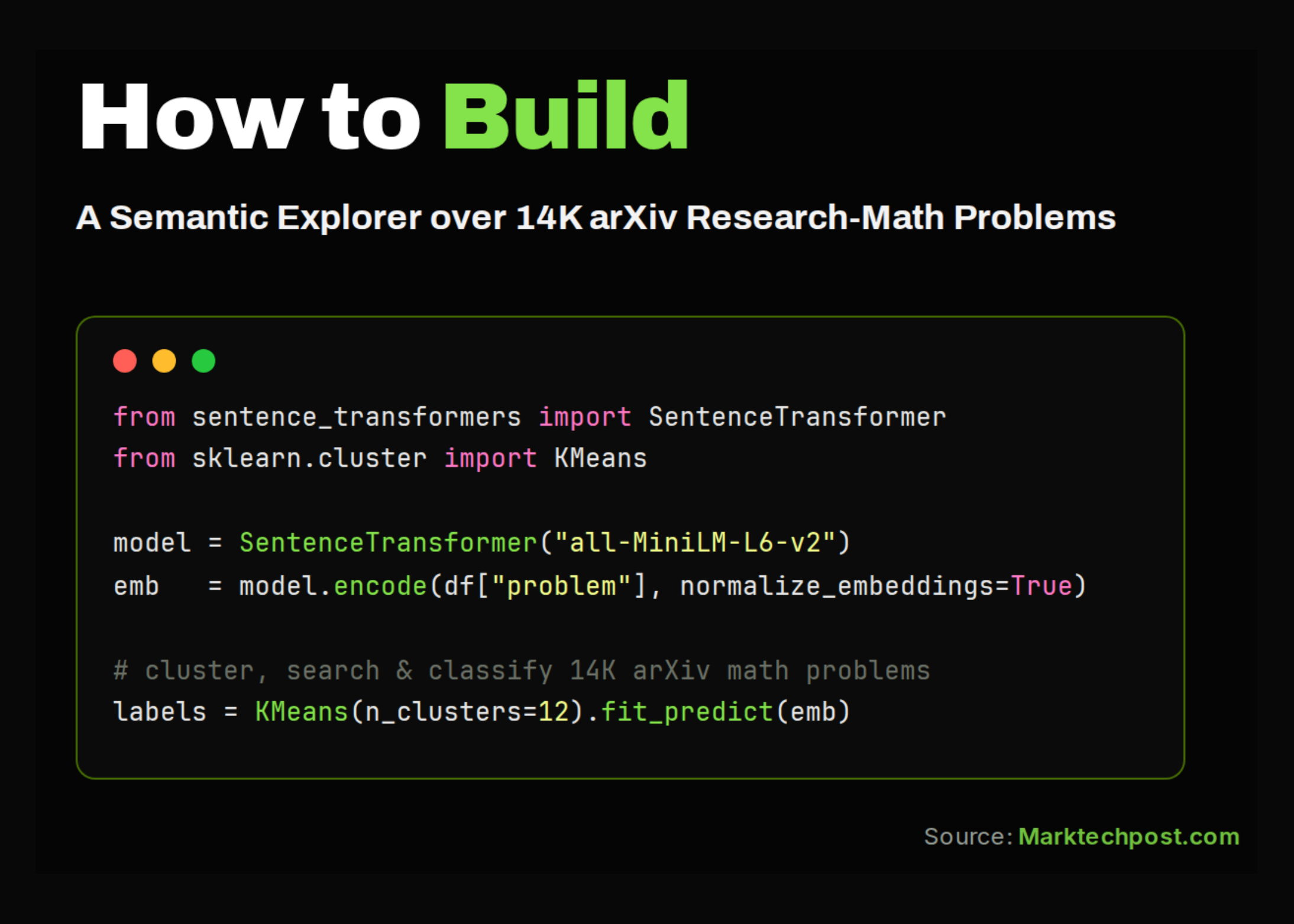
In this tutorial, we work with the amphora/ResearchMath-14k dataset, a collection of research-level mathematics problems mined from arXiv. We load the dataset, inspect its structure, and explore how the problems are distributed across mathematical fields and open-status categories. We then move beyond basic analysis by extracting field-specific keywords, generating semantic embeddings, visualizing the problem landscape, clustering related problems, and building a simple search engine over the dataset. Also, we train a classifier to predict problem status from embeddings and detect closely related or near-duplicate problems.
!pip -q install -U datasets sentence-transformers scikit-learn umap-learn \
pandas matplotlib seaborn wordcloud 2>/dev/null
import warnings, numpy as np, pandas as pd
warnings.filterwarnings("ignore")