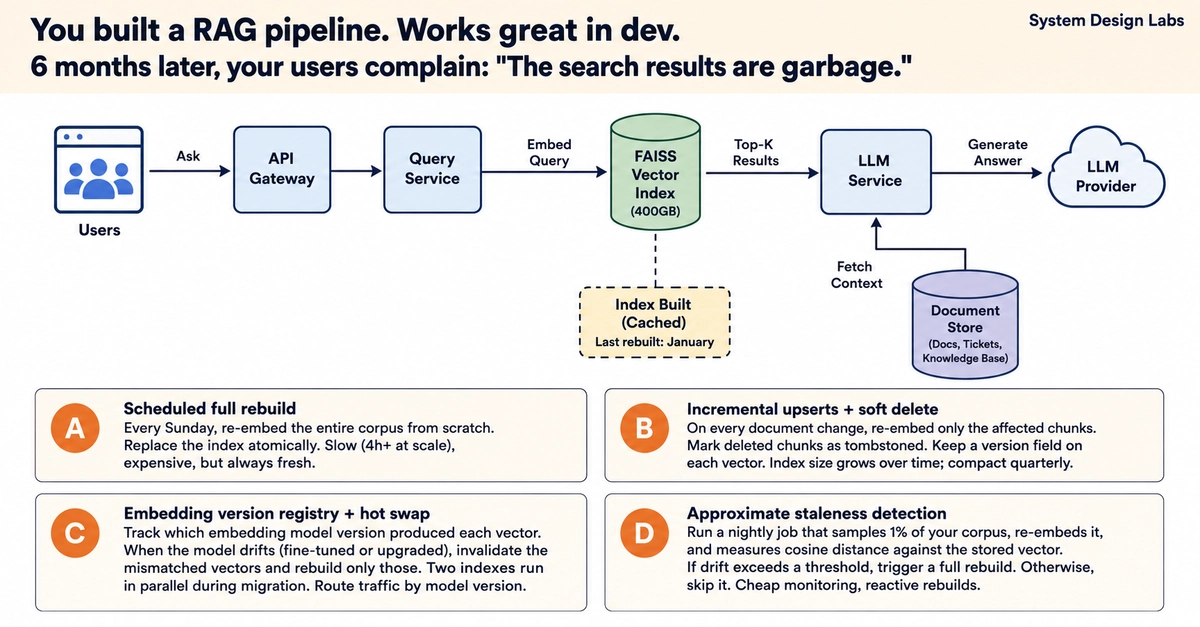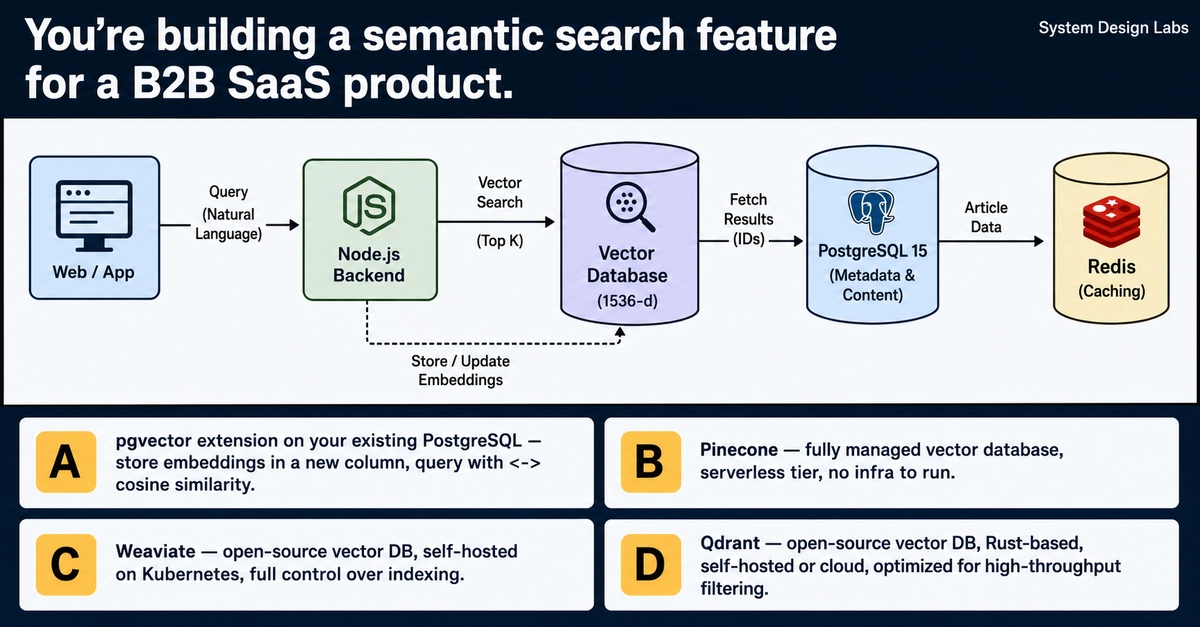
You're building a semantic search feature for a B2B SaaS product.
The corpus: 4 million support articles, docs, and user-generated tickets. Users type natural language queries. They expect Google-quality results — not keyword matching.
Your current stack: PostgreSQL 15, Redis, and a Node.js backend. The search team says ILIKE and pg_trgm aren't cutting it. Embeddings are the answer. Now you need a place to store and query 1536-dimensional vectors (OpenAI ada-002) at <100ms p99.
4 million rows. ~24GB of raw embeddings. Query volume: 300 req/s with weekend spikes to 900 req/s.
Where do you store and query those vectors?