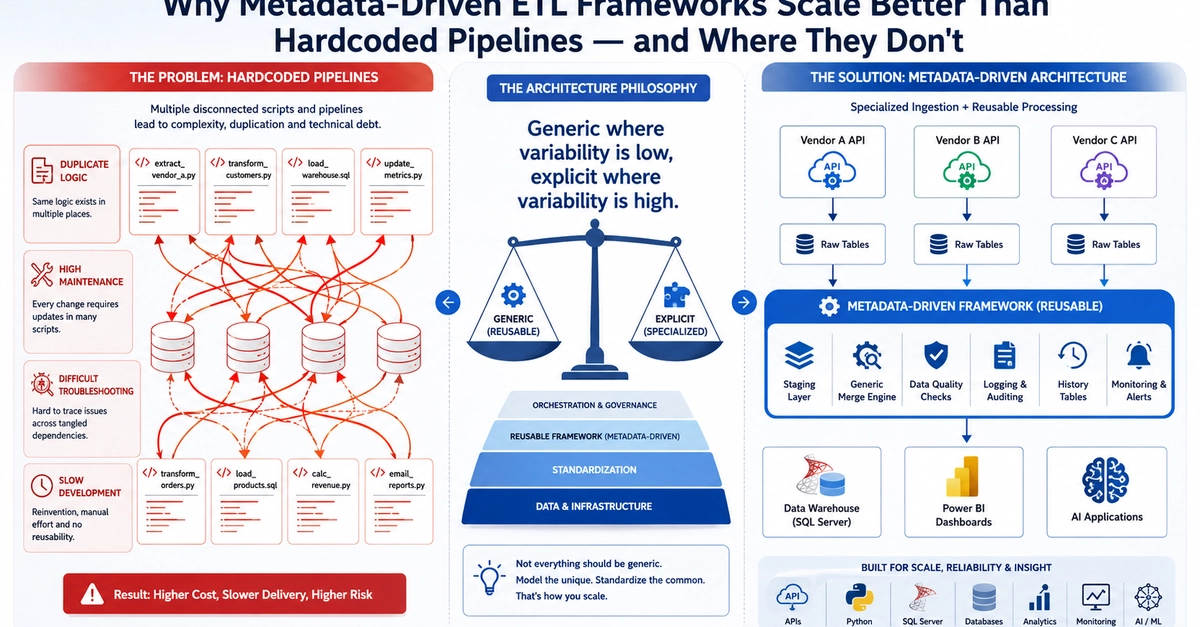
description: "Most self-healing pipelines automate retries and schema-drift detection, covering maybe 20% of real failures. Real resilience is an architecture: deterministic cores, AI for the messy edges, and human-gated repair."
"Self-healing" is the most oversold phrase in data engineering right now. Most platforms wearing the label do two things: retry failed jobs and detect schema drift on supported connectors. Both are useful. Together they cover maybe a fifth of what actually breaks pipelines in production. The rest is an architecture problem, and no feature toggle solves it.
The cost of pretending pipelines are stable
Data teams lose a remarkable amount of time here. A Fivetran/Wakefield survey of 540+ data professionals found engineers spend around 44% of their time building and rebuilding pipelines. For a typical 12-person team, that is roughly $520K a year of senior capacity spent on plumbing, before you count the cost of decisions made on stale data. The same survey found 71% say end users already act on old or error-prone data, and 66% say leadership has no idea.
That is not bad luck. It is the predictable result of running deterministic pipelines in a world that refuses to stay deterministic. A vendor renames a field, ships a new schema version without warning, and the pipeline does not degrade gracefully. It stops. Someone gets paged.