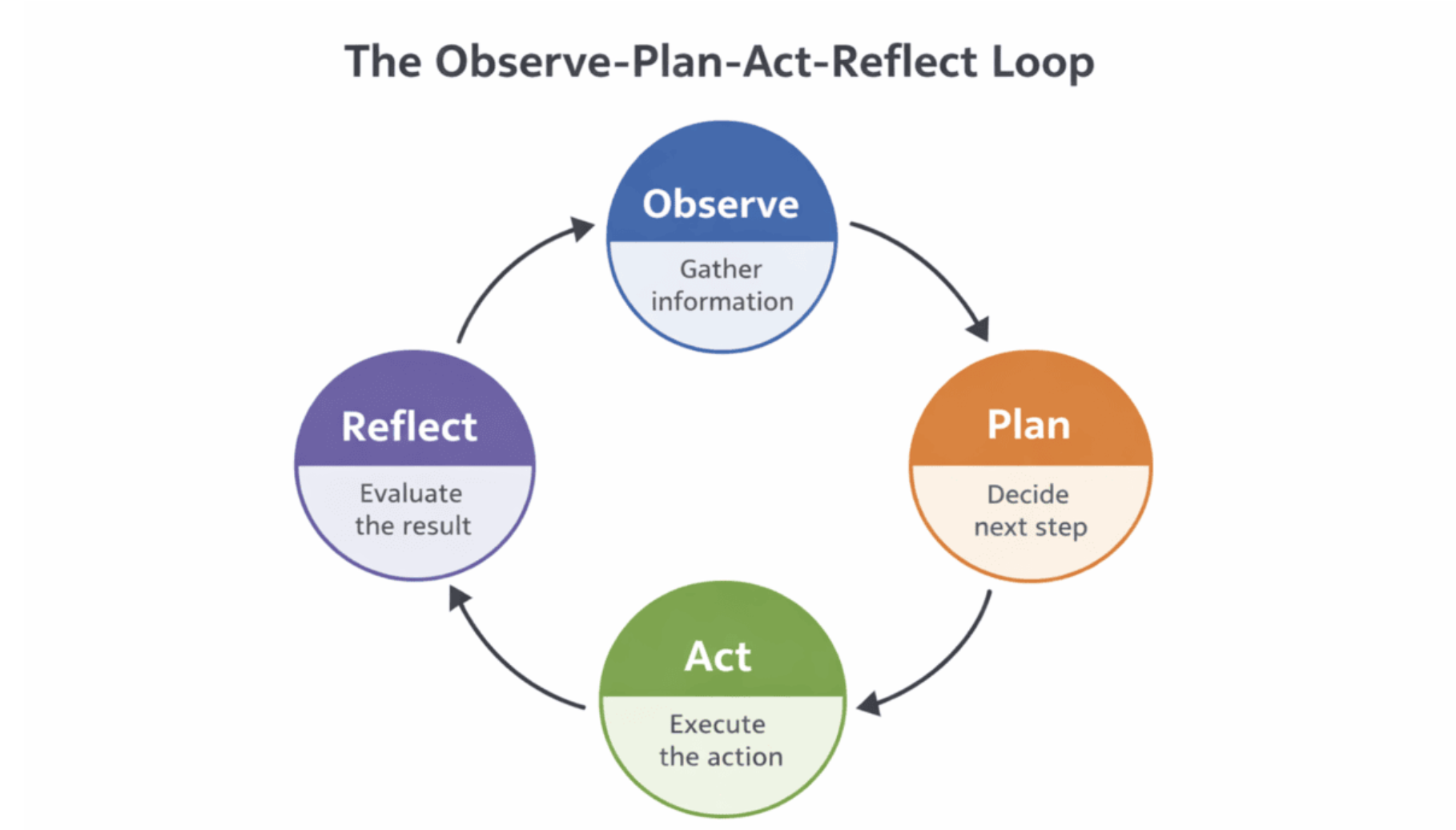
Your AI assistant gets a question wrong. A domain expert notices, types “That’s not how we calculate quarterly returns. Use the fiscal year-end date, not calendar year,” and moves on. Three weeks later, the same question comes up. The assistant gets it right this time. Not because someone retrained the model. The system remembered that correction and applied it.
This is Agent Learning from Human Feedback in action. ALHF. The idea that AI agents can improve through natural language corrections from domain experts, without the traditional retraining cycle.
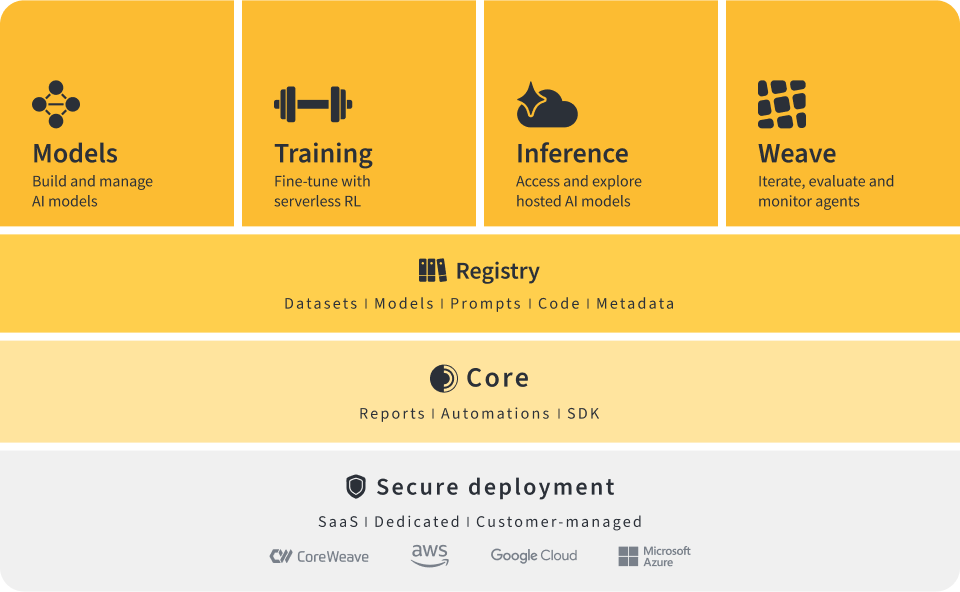
In this article, we’ll walk through what ALHF actually involves, where it differs from the RLHF approach you’ve probably heard about, and what the research and early deployments tell us about making it work. We’ll also look at how to set up a practical feedback loop using Weights & Biases. The focus here is on concepts and organizational considerations. If you’re a manager trying to understand whether this approach makes sense for your team, this is for you.
Executive summary on ALHF for busy leaders
ALHF lets AI agents adapt to your organization’s expectations through plain-language corrections from domain experts, with no retraining and no numeric reward signals. It matters because it compresses the months-long fine-tuning cycle into days or weeks, allowing people who already know the work to shape agent behavior directly. The trade-off is that it depends on feedback quality, which is messier in practice than the research assumes.