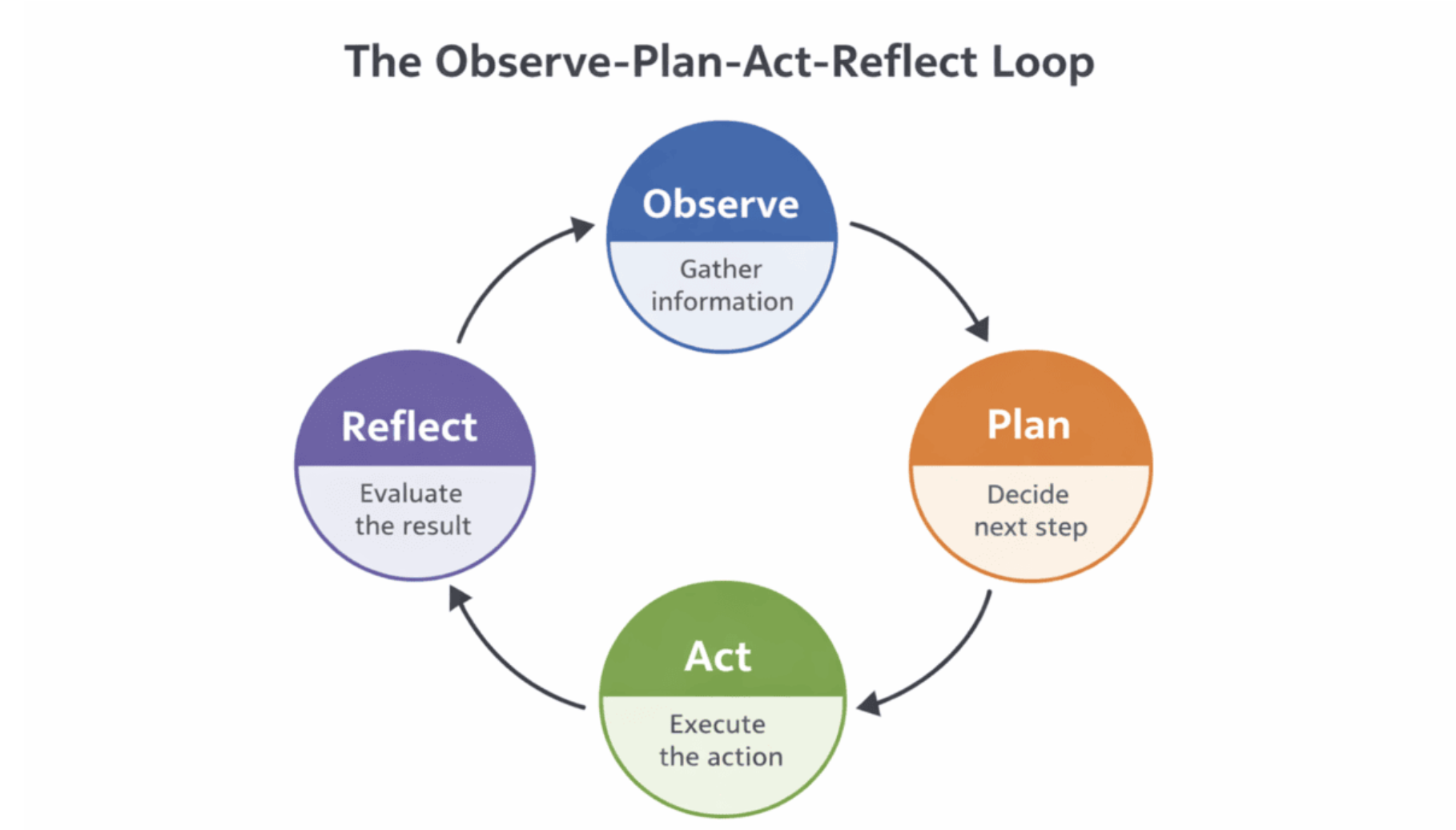
The principles of agentic reasoningWhat is agentic AI?Agentic AI refers to systems that can pursue goals by taking a sequence of actions instead of producing a single response. Traditional AI models are typically used in a request-response pattern. A user sends a prompt, the model generates an answer, and the interaction ends. Agentic systems operate differently. They interpret a task, decide what steps are required, execute those steps, and adjust their behavior as the situation evolves.An agent usually combines several components. A reasoning model determines what actions to take. Tools allow the system to interact with external systems such as search engines, databases, or APIs. Memory stores information about past steps and intermediate results. Together, these components allow the system to perform tasks that require multiple decisions rather than a single prediction.The key shift is that the model is no longer only responsible for generating text. It participates in an ongoing process that includes planning, execution, evaluation, and adaptation. Because the system acts repeatedly, mistakes can accumulate unless the agent has mechanisms to detect and correct them.This is where self-correction becomes essential. A capable agent must not only act, but also evaluate the consequences of those actions.The observe-plan-act-reflect loopMany agentic systems are built around a structured control loop that turns raw reasoning into reliable, goal-directed behavior. One of the most widely used patterns is the Observe-Plan-Act-Reflect loop.Here’s exactly how it works in practice:Observe: The agent gathers fresh information. This includes the original user request, tool outputs, API responses, current system state, or results from previous steps.Plan: The reasoning engine analyzes what has been observed and decides on the single next action (or short sequence of actions) that best advances the overall goal.Act: The agent executes the chosen step, calling a tool, running code, querying a database, generating content, or invoking an external API.Reflect: The agent evaluates the outcome. It determines whether the result is correct, incomplete, incorrect, or off-track, and then generates insights to guide the next iteration. A closed-loop control cycle for agentic AI, enabling iterative decision-making, execution, and self-correction.[/caption]This loop repeats until a stopping condition is met (goal achieved, maximum steps reached, confidence threshold passed, etc.). Each full cycle lets the agent incorporate new information and refine its strategy. When the reflect stage is implemented well, it becomes the primary mechanism for self-correction, detecting errors early, avoiding repeated mistakes, and preventing error cascades that would otherwise derail the entire workflow.Why is self-correction essential for agentic systems?In a traditional generative model, a single wrong token is annoying but harmless: the conversation simply ends. In an agentic system, that same wrong token can trigger a chain of catastrophic failures.Because agents operate in long-running loops (Observe → Plan → Act → Reflect), every decision becomes the foundation for the next one. A small error early in the sequence compounds exponentially. One bad API call, one hallucinated fact, or one misinterpreted tool output, and the entire plan collapses.The compounding error problemConsider a realistic task: “Research the latest benchmarks Grok benchmarks, build a comparison table, and publish it as a live Notion page.”Observe: The agent pulls data from three sources and misreads one release date.Plan: It constructs the entire comparison around the incorrect timeline.Act: It generates the table, creates the Notion page, and declares success.The final output is confidently wrong, and the agent has no idea.Real-world agent runs fail in exactly this way every day: malformed JSON, silent exceptions, outdated search results, or subtle hallucinations. The longer the horizon (more steps, more tools, more external state), the more fragile the system becomes.An agentic system without self-correction is just an expensive hallucination at scale.Self-correction is the minimum requirement for production agentsProduction-grade agentic systems share one non-negotiable trait: they treat every action as provisional until it is verified.This is why every serious framework in 2025–2026 bakes reflection and evaluation directly into the control loop:Reflexion-style self-critique: runs after every stepLangGraph conditional evaluator nodes: route to “success → continue” or “failure → replan.”Separate critic LLMs: score or rewrite outputsReAct with explicit verification prompts: catch errors before they propagateAgents that lack these mechanisms remain brittle demos. Agents that include them recover from bad tool calls, catch their own hallucinations, retry intelligently, and even change strategy mid-flight.True agency means taking responsibility for complex, multi-step goals in the real world. Responsibility without the ability to notice and fix mistakes is meaningless.Self-correction is therefore the foundation of any system that can honestly call itself agentic.The self-correction promise: Mechanics of autonomous improvementThe real power of agentic AI emerges when self-correction stops being a defensive patch and becomes an engine of continuous, autonomous improvement. Instead of simply avoiding failure, well-designed agents actually get smarter with every cycle. Here are the three core mechanics that make this possible.1. Iterative feedback loopsSelf-correction begins with tight, rapid feedback. After every action, the agent immediately evaluates its own output against the original goal, success criteria, or a set of verifiable metrics.This is far more than “did it work?”, Modern implementations use structured scoring:Binary success/failureNumerical confidence scores (0–1)Rubric-based evaluation (relevance, completeness, accuracy, safety)LLM-as-a-Judge prompts with chain-of-thought reasoningWhen the score falls below a threshold, the agent automatically triggers replanning or repair steps. Because the loop is fast and cheap, the system can iterate 5–20 times on a single sub-task without human intervention. The result is not just error recovery, it is measurable, progressive improvement in output quality over successive attempts.2. Memory and permanent failure avoidanceOne-shot reflection is useful, but true autonomy requires persistent memory of failure.Modern agent architectures maintain two memory layers:Short-term working memory (the current loop context)Long-term episodic memory (vector store or graph database of past trajectories)Every failed or low-scoring execution is stored with:The original planThe exact error or critiqueThe successful recovery path (if one was found)The final outcomeWhen the agent encounters a similar situation later, it retrieves the most relevant failure cases and proactively avoids repeating the same mistake. This turns every past error into institutional knowledge. Over time, the agent develops “learned instincts”; it becomes systematically better at the specific domain or workflow it repeatedly tackles.3. Multi-agent systems as digital colleaguesIn multi-agent setups (LangGraph teams, CrewAI, AutoGen, MetaGPT-style hierarchies), different agents play distinct roles:Planner / Researcher: gathers and reasonsExecutor / Tool User: performs actionsCritic / Evaluator: ruthlessly scores outputRefiner / Editor: rewrites or repairsVerifier: runs final consistency checksThese digital colleagues argue, critique, and cross-verify each other’s work exactly like a high-performing human team. A mistake that slips past one agent can be caught by another. The collective intelligence dramatically reduces blind spots and produces outputs that no single agent could achieve on its own.Together, these three mechanics: rapid iterative feedback, persistent failure memory, and collaborative multi-agent critique, transform self-correction from a safety net into a genuine learning system. The agent doesn’t just fix mistakes; it evolves.
Agentic AI self-correction: How to build systems that fix their own mistakes
The principles of agentic reasoningWhat is agentic AI?Agentic AI refers to systems that can pursue goals by taking a sequence of actions instead of producing a single response. Traditional AI models are typically used in a request-response pattern. A user sends a prompt, the model generates an answer, and the interaction ends. Agentic systems operate differently. They interpret a task, decide what steps are required, execute those steps, and adjust their behavior as the situation evolves.An agent usually combines several components. A reasoning model determines what actions to take. Tools allow the system to interact with external systems such as search engines, databases, or APIs. Memory stores information about past steps and intermediate results. Together, these components allow the system to perform tasks that require multiple decisions rather than a single prediction.The key shift is that the model is no longer only responsible for generating text. It participates in an ongoing process that includes planning, execution, evaluation, and adaptation. Because the system acts repeatedly, mistakes can accumulate unless the agent has mechanisms to detect and correct them.This is where self-correction becomes essential. A capable agent must not only act, but also evaluate the consequences of those actions.The observe-plan-act-reflect loopMany agentic systems are built around a structured control loop that turns raw reasoning into reliable, goal-directed behavior. One of the most widely used patterns is the Observe-Plan-Act-Reflect loop.Here’s exactly how it works in practice:Observe: The agent gathers fresh information. This includes the original user request, tool outputs, API responses, current system state, or results from previous steps.Plan: The reasoning engine analyzes what has been observed and decides on the single next action (or short sequence of actions) that best advances the overall goal.Act: The agent executes the chosen step, calling a tool, running code, querying a database, generating content, or invoking an external API.Reflect: The agent evaluates the outcome. It determines whether the result is correct, incomplete, incorrect, or off-track, and then generates insights to guide the next iteration. A closed-loop control cycle for agentic AI, enabling iterative decision-making, execution, and self-correction.[/caption]This loop repeats until a stopping condition is met (goal achieved, maximum steps reached, confidence threshold passed, etc.). Each full cycle lets the agent incorporate new information and refine its strategy. When the reflect stage is implemented well, it becomes the primary mechanism for self-correction, detecting errors early, avoiding repeated mistakes, and preventing error cascades that would otherwise derail the entire workflow.Why is self-correction essential for agentic systems?In a traditional generative model, a single wrong token is annoying but harmless: the conversation simply ends. In an agentic system, that same wrong token can trigger a chain of catastrophic failures.Because agents operate in long-running loops (Observe → Plan → Act → Reflect), every decision becomes the foundation for the next one. A small error early in the sequence compounds exponentially. One bad API call, one hallucinated fact, or one misinterpreted tool output, and the entire plan collapses.The compounding error problemConsider a realistic task: “Research the latest benchmarks Grok benchmarks, build a comparison table, and publish it as a live Notion page.”Observe: The agent pulls data from three sources and misreads one release date.Plan: It constructs the entire comparison around the incorrect timeline.Act: It generates the table, creates the Notion page, and declares success.The final output is confidently wrong, and the agent has no idea.Real-world agent runs fail in exactly this way every day: malformed JSON, silent exceptions, outdated search results, or subtle hallucinations. The longer the horizon (more steps, more tools, more external state), the more fragile the system becomes.An agentic system without self-correction is just an expensive hallucination at scale.Self-correction is the minimum requirement for production agentsProduction-grade agentic systems share one non-negotiable trait: they treat every action as provisional until it is verified.This is why every serious framework in 2025–2026 bakes reflection and evaluation directly into the control loop:Reflexion-style self-critique: runs after every stepLangGraph conditional evaluator nodes: route to “success → continue” or “failure → replan.”Separate critic LLMs: score or rewrite outputsReAct with explicit verification prompts: catch errors before they propagateAgents that lack these mechanisms remain brittle demos. Agents that include them recover from bad tool calls, catch their own hallucinations, retry intelligently, and even change strategy mid-flight.True agency means taking responsibility for complex, multi-step goals in the real world. Responsibility without the ability to notice and fix mistakes is meaningless.Self-correction is therefore the foundation of any system that can honestly call itself agentic.The self-correction promise: Mechanics of autonomous improvementThe real power of agentic AI emerges when self-correction stops being a defensive patch and becomes an engine of continuous, autonomous improvement. Instead of simply avoiding failure, well-designed agents actually get smarter with every cycle. Here are the three core mechanics that make this possible.1. Iterative feedback loopsSelf-correction begins with tight, rapid feedback. After every action, the agent immediately evaluates its own output against the original goal, success criteria, or a set of verifiable metrics.This is far more than “did it work?”, Modern implementations use structured scoring:Binary success/failureNumerical confidence scores (0–1)Rubric-based evaluation (relevance, completeness, accuracy, safety)LLM-as-a-Judge prompts with chain-of-thought reasoningWhen the score falls below a threshold, the agent automatically triggers replanning or repair steps. Because the loop is fast and cheap, the system can iterate 5–20 times on a single sub-task without human intervention. The result is not just error recovery, it is measurable, progressive improvement in output quality over successive attempts.2. Memory and permanent failure avoidanceOne-shot reflection is useful, but true autonomy requires persistent memory of failure.Modern agent architectures maintain two memory layers:Short-term working memory (the current loop context)Long-term episodic memory (vector store or graph database of past trajectories)Every failed or low-scoring execution is stored with:The original planThe exact error or critiqueThe successful recovery path (if one was found)The final outcomeWhen the agent encounters a similar situation later, it retrieves the most relevant failure cases and proactively avoids repeating the same mistake. This turns every past error into institutional knowledge. Over time, the agent develops “learned instincts”; it becomes systematically better at the specific domain or workflow it repeatedly tackles.3. Multi-agent systems as digital colleaguesIn multi-agent setups (LangGraph teams, CrewAI, AutoGen, MetaGPT-style hierarchies), different agents play distinct roles:Planner / Researcher: gathers and reasonsExecutor / Tool User: performs actionsCritic / Evaluator: ruthlessly scores outputRefiner / Editor: rewrites or repairsVerifier: runs final consistency checksThese digital colleagues argue, critique, and cross-verify each other’s work exactly like a high-performing human team. A mistake that slips past one agent can be caught by another. The collective intelligence dramatically reduces blind spots and produces outputs that no single agent could achieve on its own.Together, these three mechanics: rapid iterative feedback, persistent failure memory, and collaborative multi-agent critique, transform self-correction from a safety net into a genuine learning system. The agent doesn’t just fix mistakes; it evolves.