Hey Devs! 👋
Building a Retrieval-Augmented Generation (RAG) system for standard Q&A is relatively straightforward. But when you move into the legal domain, standard setups fall apart. Accuracy isn't a vanity metric here—hallucinations can have actual legal consequences, and citations are non-negotiable.
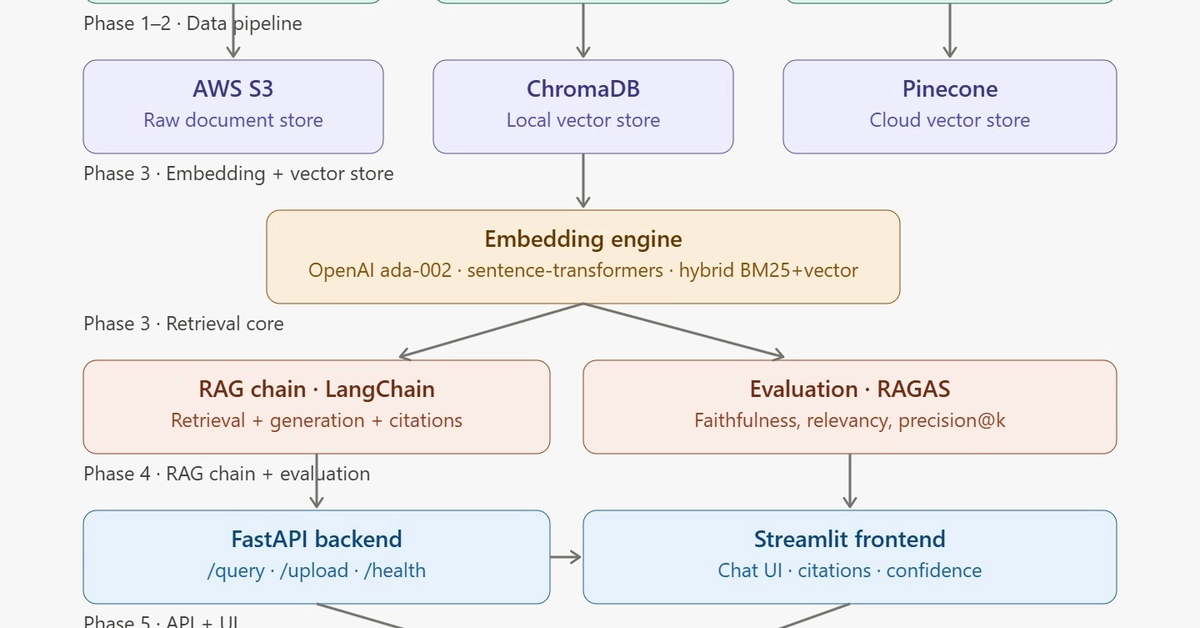
I recently mapped out and built an end-to-end architecture for a Legal RAG System designed to handle complex legal documents with high precision. Here is the architectural blueprint and stack breakdown.
Phase 1–2: The Heavy-Lifting Data Pipeline
Document Ingestion: Handling raw PDFs, DOCX, and TXT files. Legal documents are notoriously long and structurally dense.





