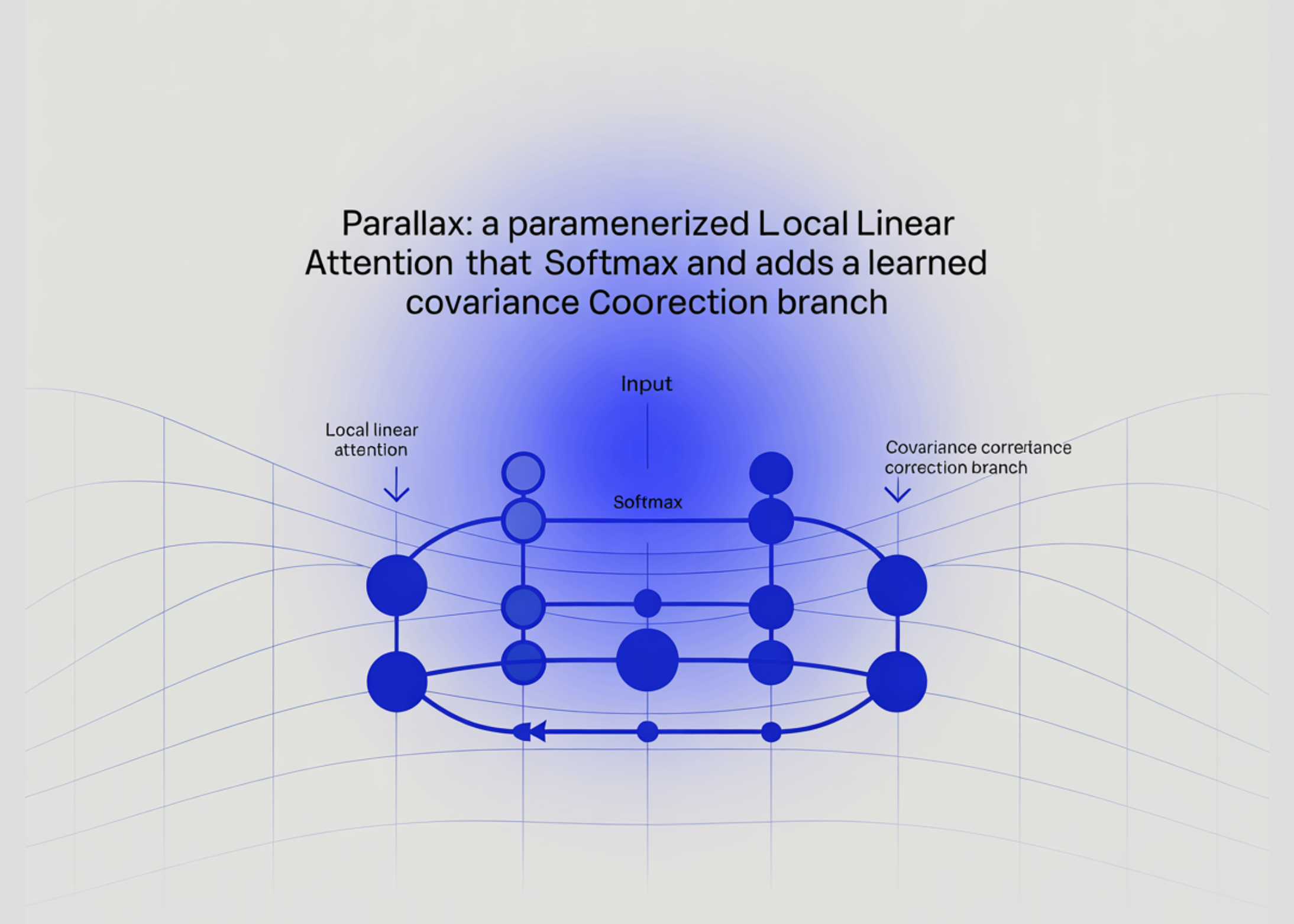
The Transformer’s attention mechanism has barely changed since 2017. Most efficiency work has tried to replace softmax attention outright. A new paper takes a different route. It keeps softmax attention and bolts on a correction branch.
A team of researchers from Northwestern University, Tilde Research, and University of Washington introduce a parameterized Local Linear Attention called ‘Parallax’ that scales to LLM pretraining and codesigns with Muon.
Parallax does not chase efficiency by cutting compute. It adds compute deliberately, then makes that compute cheaper to run on modern GPUs.
What is Parallax
Parallax builds on Local Linear Attention (LLA). LLA comes from the test-time regression framework. That framework reads attention as a regression solver over key-value pairs.