
这段 Eye on AI的访谈视频深度探讨了为什么 Transformer 架构无法承载 AI 的未来,并详细介绍了一种名为 Power Retention(幂次保留机制) 的全新架构解决方案 。
受访者是 Jacob(Manifest AI 的联合创始人,卡内基梅隆大学计算机学士、Mila 实验室 AI 博士)。
以下是视频内容的超详细拆解(包含时间戳索引):
一、 当前 Transformer 架构的核心瓶颈:长文本的二次方成本
参数扩展与输入扩展的脱节 [05:18]:
这段 Eye on AI的访谈视频深度探讨了为什么 Transformer 架构无法承载 AI 的未来,并详细介绍了一种名为 Power Retention(幂次保留机制) 的全新架构解决方案...
这段 Eye on AI的访谈视频深度探讨了为什么 Transformer 架构无法承载 AI 的未来,并详细介绍了一种名为 Power Retention(幂次保留机制) 的全新架构解决方案 。
受访者是 Jacob(Manifest AI 的联合创始人,卡内基梅隆大学计算机学士、Mila 实验室 AI 博士)。
以下是视频内容的超详细拆解(包含时间戳索引):
一、 当前 Transformer 架构的核心瓶颈:长文本的二次方成本
参数扩展与输入扩展的脱节 [05:18]:

这期播客是 Jacob Effron 主持的 Unsupervised Learning 嘉宾是 AI 领域的传奇研究员 Lukasz Kaiser (他是奠定现代 AI 基础的...

http://www.youtube.com/watch?v=y6pfgiTjHXQ 这段视频详细讨论了 AI 行业当前面临的核心危机:“缩放定律”(Scaling...

Originally published on my blog. Cross-posted here with a canonical link. In June 2017, a...
Since its introduction, the transformer architecture has become the cornerstone of modern artificial...
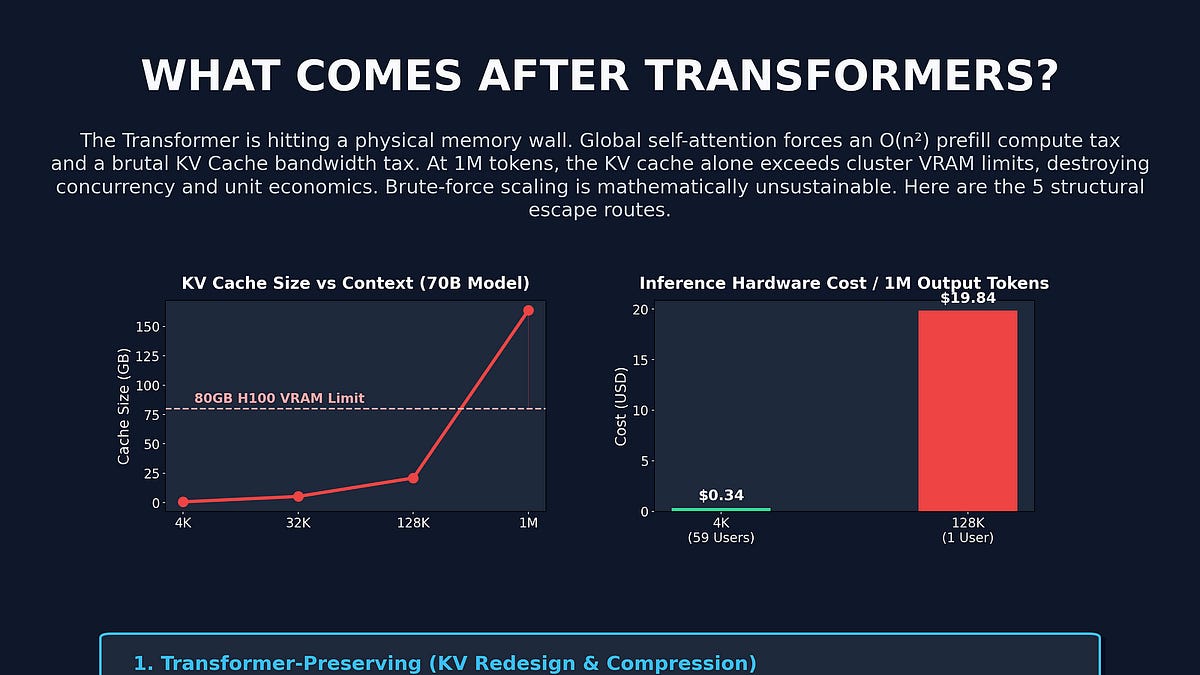
A clear guide to the new architectures battling the transformer’s memory and inference bottlenecks.

你知道吗?2026 年中期,在生产环境部署 671B 参数的 DeepSeek-R1 仍然需要 8 张 H100,硬件成本约 20 万美元。但清华大学 MADSys 实验室的开源项目早在 2024...


