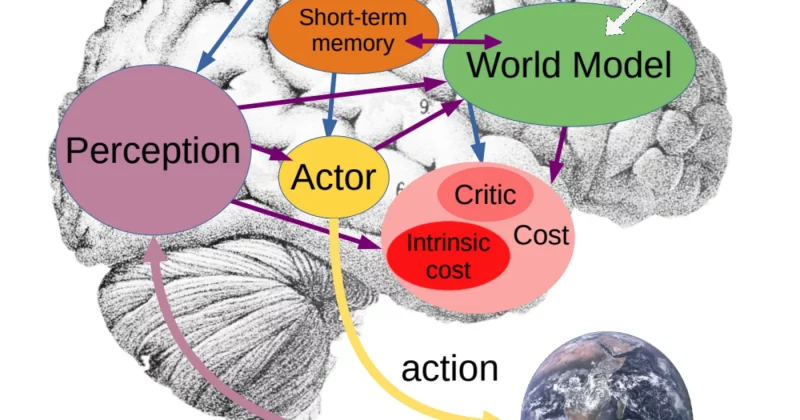
[Paper Notes] JEPA: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture🔗
TL;DR: JEPA learns a a generalized semantic representation with less data pairs by predicting missing information in the embedding space, which helps it disregard unnecessary noisy from input(pixel)-level details and learns at a higher abstraction level with good semantic generalization.
1. Innovation & Significance
The Bottleneck:
Pixel level pre-training paired & data augmentation are strongly biased towards trained data distribution, hard to determine proper generalization and level of abstraction.