Back to Articles
Author: Dan Su
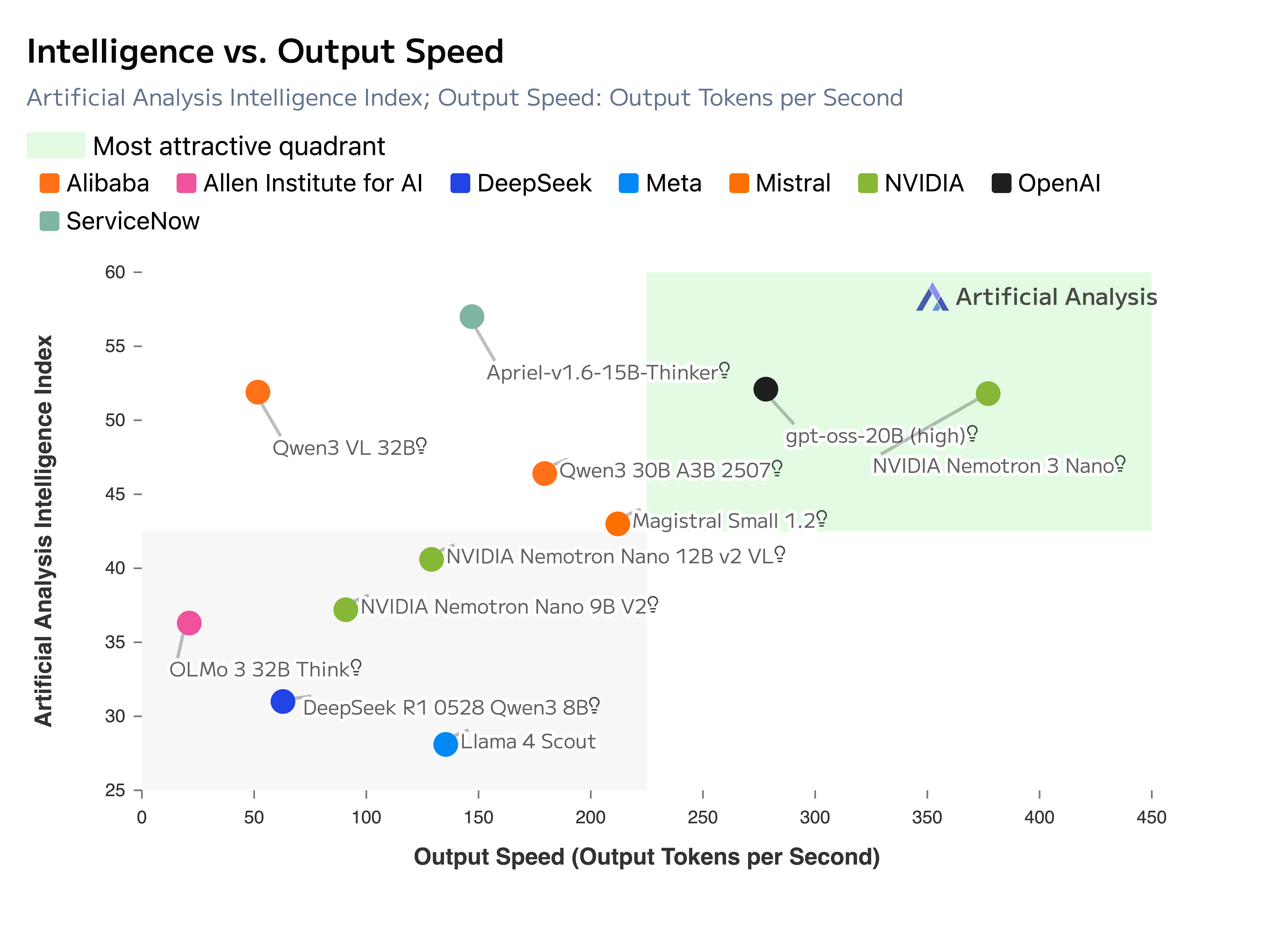
In large-scale LLM development, the question is no longer simply how much data a model sees. It is also whether the data contains enough structured learning signals. General web, code, math, multilingual, and domain data provide a broad base. Task-seeded synthetic Q&A complements them by adding compact, task-structured examples with a clear information need, a constrained response space, and explanations that connect evidence to an answer. In a 100B-token continuation experiment on the Nemotron-3 Nano model, task-seeded SDG improved MMLU-Pro by +1.8, average code by +1.9, commonsense understanding by +1.6, and GPQA by +11.1, while average math remained stable.
This post describes a task-seeded synthetic Q&A generation workflow developed for Nemotron-family training, including Ultra and Super training runs. The workflow uses training splits from broad public task families as capability seeds, generates new task-aligned examples, enriches them with reasoning and relevant knowledge, and filters them into curated synthetic datasets. Held-out evaluation and test data are excluded from generation. Downstream training recipes can then decide how to mix those datasets with the broader corpus.