This article is part of our coverage of the latest in AI research.
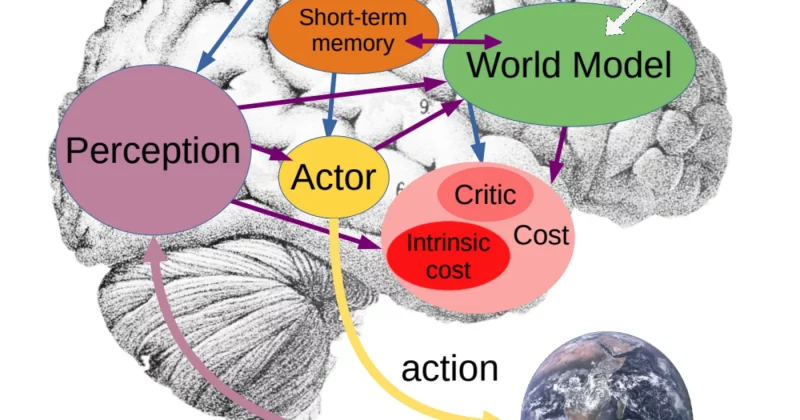
Researchers at Meta have introduced VL-JEPA, a vision-language model built on a Joint Embedding Predictive Architecture (JEPA). Unlike traditional models that focus on generating text word-by-word, VL-JEPA focuses on predicting abstract representations of the world.
This approach makes the model significantly more efficient and capable; it achieves stronger performance than standard vision-language models (VLMs) while using only 50% of the trainable parameters. Beyond its efficiency, the model supports a wide range of applications without requiring architectural modifications. VL-JEPA represents a fundamental shift in model design, moving beyond simple token prediction to a system capable of understanding representations and modeling the physical world.
The shortcomings of classic VLMs
To understand why this architecture matters, it is necessary to look at the limitations of current systems. Advanced AI requires the ability to understand, reason, and act within the physical world to assist humans. Current approaches typically rely on large vision language models (VLMs) that generate tokens. These models take visual inputs and textual queries and generate a textual response autoregressively, one token at a time.