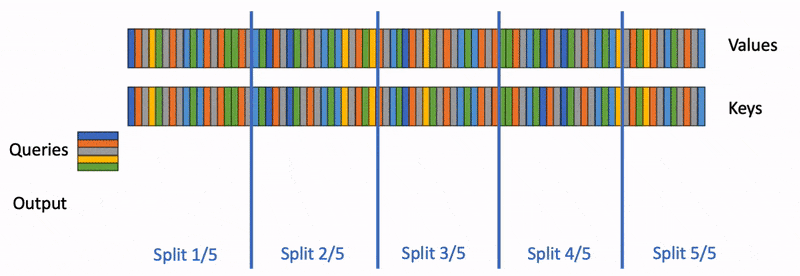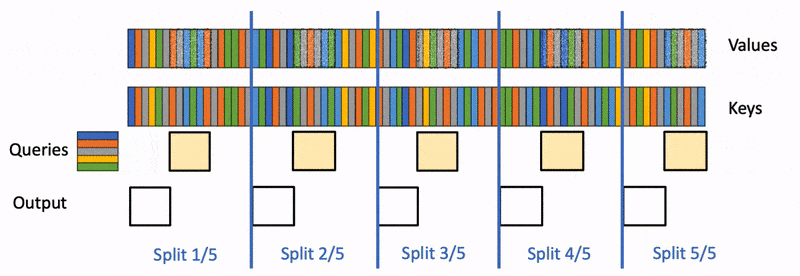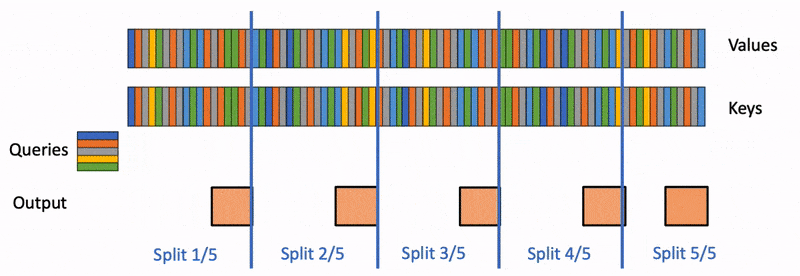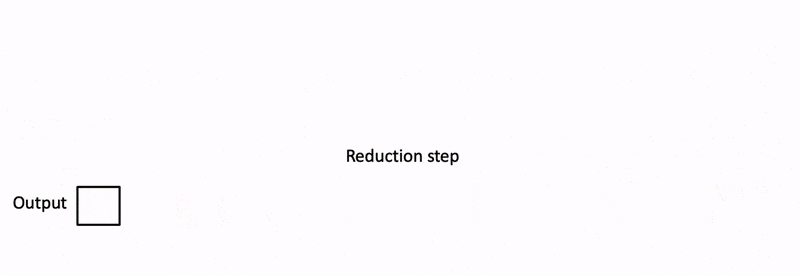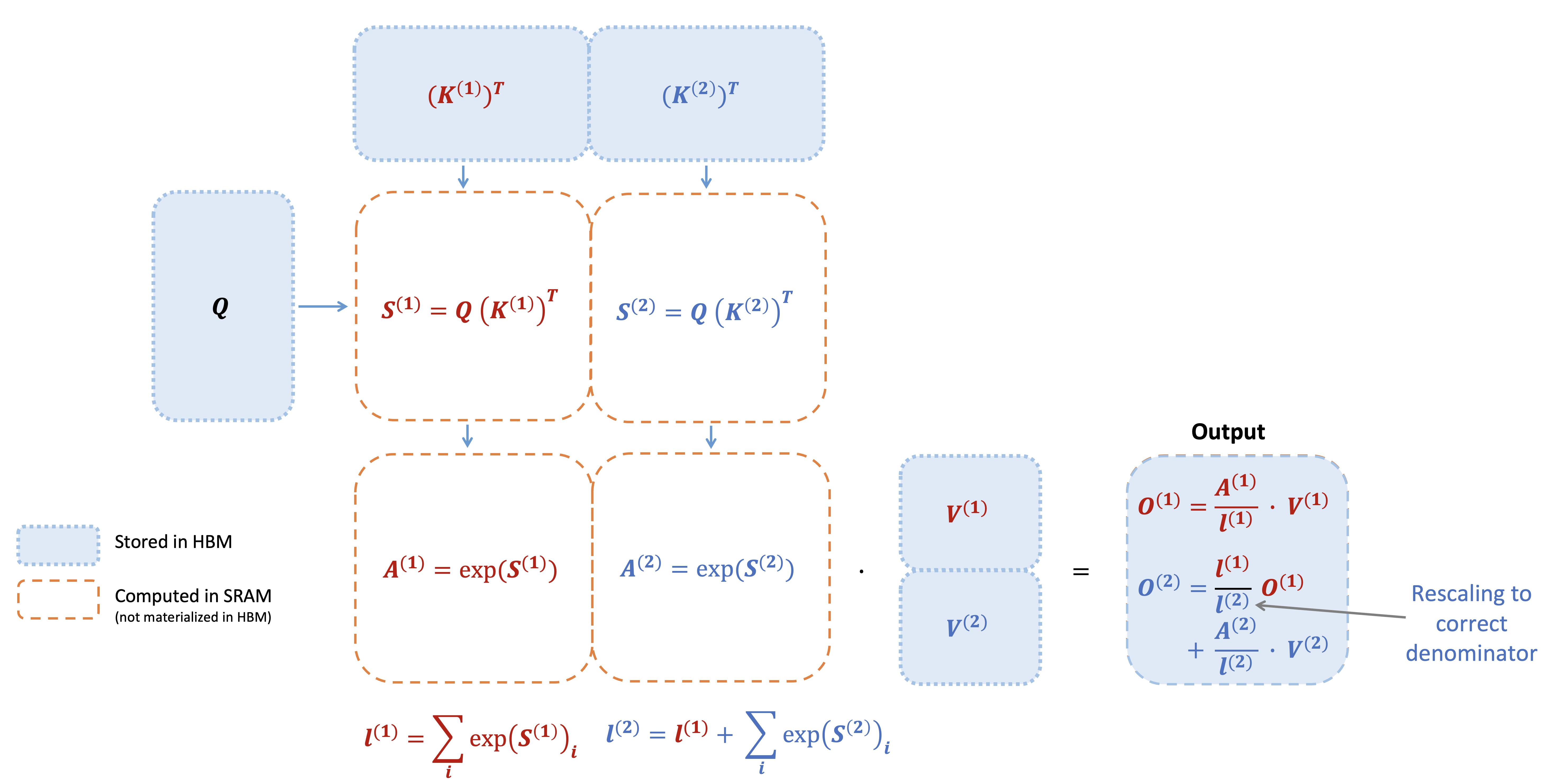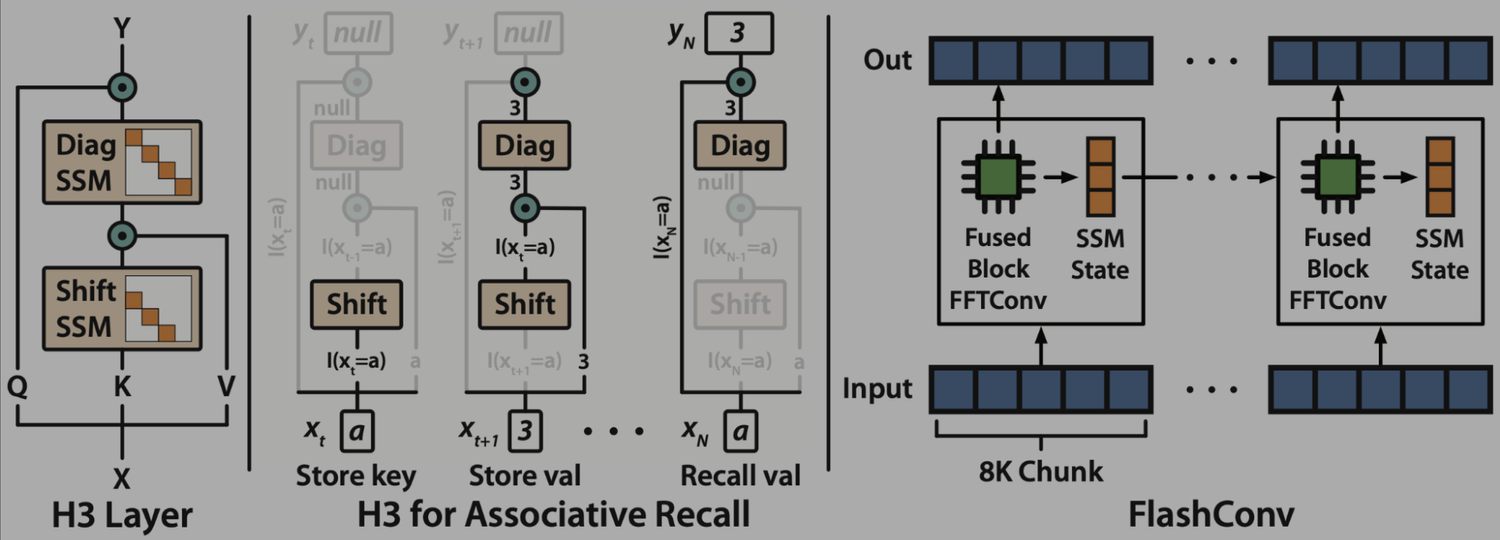
State space models (SSMs) are a promising alternative to attention – they scale nearly-linearly with sequence length instead of quadratic. However, SSMs often run slower than optimized implementations of attention out of the box, since they have low FLOP utilization on GPU. How can we make them run faster? In this blog post, we’ll go over FlashConv, our new technique for speeding up SSMs. We’ll see how in language modeling, this helped us train SSM-based language models (with almost no attention!) up to 2.7B parameters – and run inference 2.4x faster than Transformers.In our blog post on Hazy Research, we talk about some of the algorithmic innovations that helped us train billion-parameter language models with SSMs for the first time.Figure 1. H3 model architecture and FlashConv.A Primer on State Space ModelsState space models (SSMs) are a classic primitive from signal processing, and recent work from our colleagues at Stanford has shown that they are strong sequence models, with the ability to model long-range dependencies – they achieved state-of-the-art performance across benchmarks like LRA and on tasks like speech generation.For the purposes of this blog post, there are a few important properties of SSMs to know:They generate a sequence length-long convolution during trainingThey admit a recurrent formulation, which makes it possible to stop and restart the computation at any point in the convolutionThe convolution dominates the computation time during training – so speeding it up is the key bottleneck.FlashConv: Breaking the BottleneckSo how do you efficiently compute a convolution that is as long as the input sequence (potentially thousands of tokens)?FFT Convolution The first step is using the convolution theorem. Naively, computing a convolution of length N over a sequence of length N takes $O(N^2)$ time. The convolution theorem says that we can compute it as a sequence of Fast Fourier Transforms (FFTs) instead. If you want to compute the convolution between a signal $u$ and a convolution kernel $k$, you can do it as follows:$iFFT(FFT(u) \odot FFT(k)),$where $\odot$ denotes pointwise multiplication. This takes the runtime from $O(N^2)$ to $O(N \log N)$.So we can just use torch.fft, and outperform attention:Figure 2. The PyTorch FFT convolution vs. FlashAttention.Wait… the asymptotic performance looks good, but the FFT convolution is still slower than attention at sequence lengths <2K (which is where most models are trained). Can we make that part faster?Fused FFT Convolution Let’s look at what the PyTorch code actually looks like:u_f = torch.fft.fft(u)
FlashConv: Speeding up state space models
State space models (SSMs) are a promising alternative to attention – they scale nearly-linearly with sequence length instead of quadratic. However, SSMs often run slower than optimized implementations of attention out of the box, since they have low FLOP utilization on GPU. How can we make them run faster? In this blog post, we’ll go over FlashConv, our new technique for speeding up SSMs. We’ll see how in language modeling, this helped us train SSM-based language models (with almost no attention!) up to 2.7B parameters – and run inference 2.4x faster than Transformers.In our blog post on Hazy Research, we talk about some of the algorithmic innovations that helped us train billion-parameter language models with SSMs for the first time.Figure 1. H3 model architecture and FlashConv.A Primer on State Space ModelsState space models (SSMs) are a classic primitive from signal processing, and recent work from our colleagues at Stanford has shown that they are strong sequence models, with the ability to model long-range dependencies – they achieved state-of-the-art performance across benchmarks like LRA and on tasks like speech generation.For the purposes of this blog post, there are a few important properties of SSMs to know:They generate a sequence length-long convolution during trainingThey admit a recurrent formulation, which makes it possible to stop and restart the computation at any point in the convolutionThe convolution dominates the computation time during training – so speeding it up is the key bottleneck.FlashConv: Breaking the BottleneckSo how do you efficiently compute a convolution that is as long as the input sequence (potentially thousands of tokens)?FFT Convolution The first step is using the convolution theorem. Naively, computing a convolution of length N over a sequence of length N takes $O(N^2)$ time. The convolution theorem says that we can compute it as a sequence of Fast Fourier Transforms (FFTs) instead. If you want to compute the convolution between a signal $u$ and a convolution kernel $k$, you can do it as follows:$iFFT(FFT(u) \odot FFT(k)),$where $\odot$ denotes pointwise multiplication. This takes the runtime from $O(N^2)$ to $O(N \log N)$.So we can just use torch.fft, and outperform attention:Figure 2. The PyTorch FFT convolution vs. FlashAttention.Wait… the asymptotic performance looks good, but the FFT convolution is still slower than attention at sequence lengths <2K (which is where most models are trained). Can we make that part faster?Fused FFT Convolution Let’s look at what the PyTorch code actually looks like:u_f = torch.fft.fft(u)