Flash Attention: what it does and why it matters
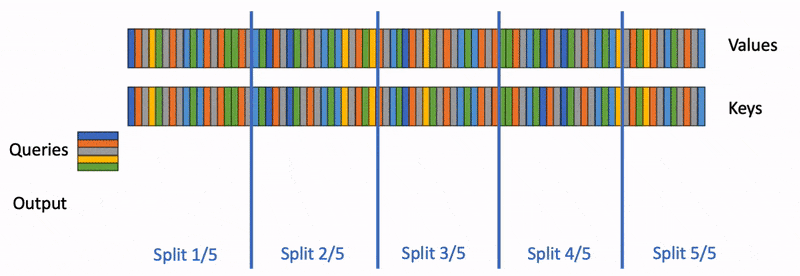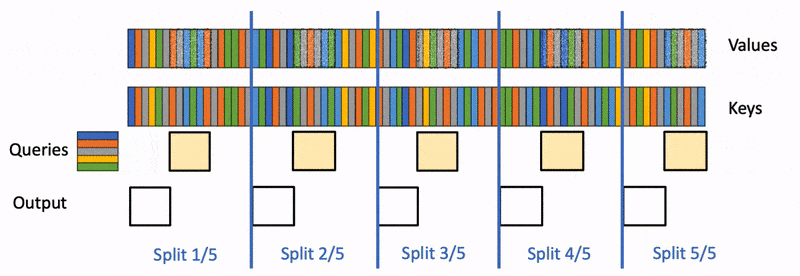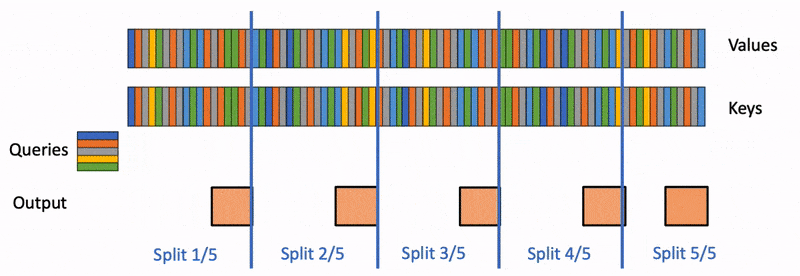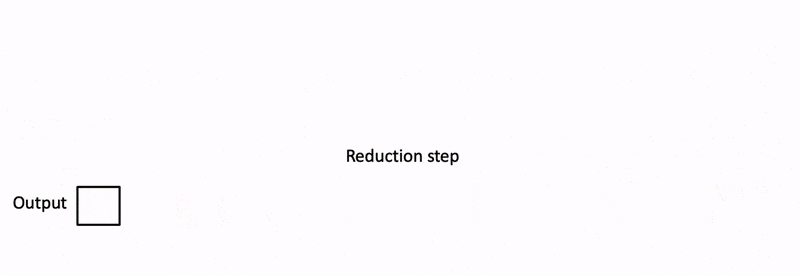
You have a single H100 with 80 GB of VRAM. The Llama 3.1 70B model fits — barely, at 140 GB in FP16, so you're running at 4-bit quantization and have maybe 5–8 GB of KV cache space left for a long-context workload. The model is fast enough at 8K context, so you push it to 32K for a RAG pipeline. It's still fine. Then you push it to 128K for a document-summary task, and suddenly the attention layer alone is spending 3 seconds per forward pass, 85% of which is just moving data between HBM and SRAM, not doing math. The CUDA kernel occupancy graph tells the story: green compute bars are tiny, grey memory-stall bars are huge. The GPU is bandwidth-bound, and vanilla attention is the cause.
Flash Attention is the algorithm that fixes this by restructuring the attention computation itself — not approximate, not sparse, not quantized, just IO-aware. Here is what it does, how the three versions differ, and where it stops helping.
Why this matters in practice
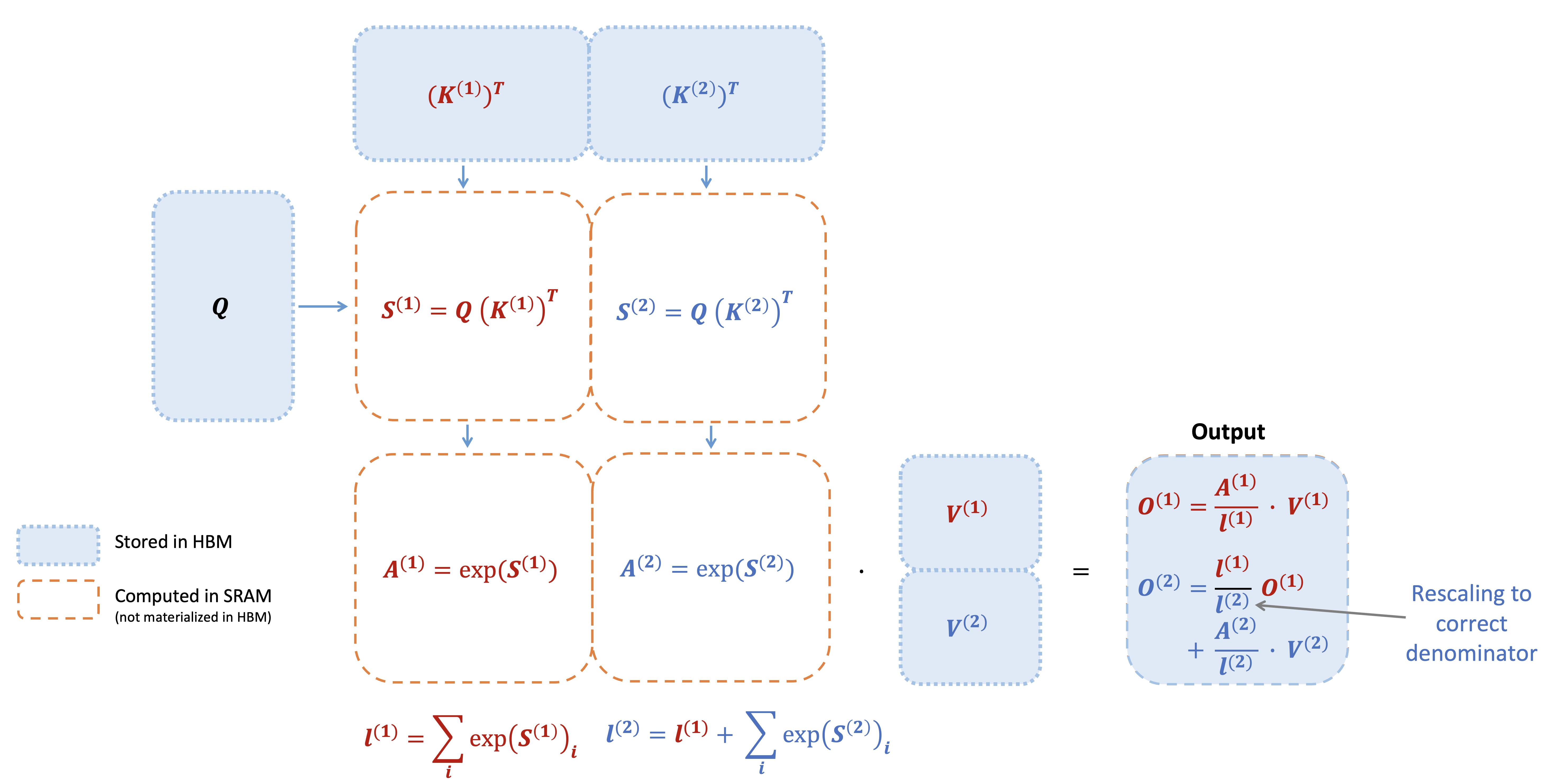
The attention mechanism is the core of every transformer: compute a similarity matrix S = Q K^T, normalize it with softmax P = softmax(S), and use it as weights over values O = P V. The problem is that for sequence length N and head dimension d, the S and P matrices are N×N, and writing them to GPU HBM (high-bandwidth memory) and reading them back is the bottleneck, not the matrix multiplies themselves.