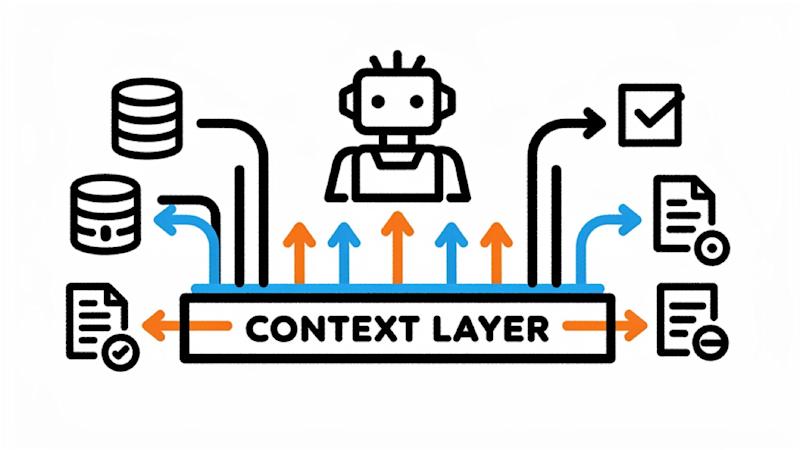
Count the systems behind your AI agent. A vector database for embeddings. A separate cache for LLM responses. A memory service for conversation state. A pipeline syncing data from Postgres. Probably a queue. Maybe a feature store. Now count the things that go wrong when one of them is out of sync with the others.Most production agent failures aren't model failures. They're context failures: the data the agent needed was somewhere in the stack, just not where the agent could see it, not fresh, or not connected to what came before. So teams swap models, tweak prompts, and tune the temperature. The failures keep coming back. The fix isn't a smarter prompt. It's a context engine: the platform layer that handles retrieval, memory, caching, and freshness as one coordinated stack instead of five disconnected ones.This guide covers what a context engine is, how it fits into agent architecture, where traditional retrieval-augmented generation (RAG) runs into limits, and how Redis powers the context layer in production.A context engine is the layer that gets the right information in front of an AI agent at the right time. It sits between your data and your agent, doing all the work of finding, ranking, and assembling context before the agent calls the model.Without one, every agent in your stack rolls its own retrieval logic, hits a different mix of databases and APIs, and ends up with inconsistent context. With one, all of that lives behind a single coordinated pipeline. The agent asks for what it needs and gets a curated payload back, every time.The category exists because LLMs don't know your data. They have to be told, on every call, what's relevant, and what's relevant depends on the user, the session, the workflow, and what just happened two turns ago. Context engineering, the practice of curating what enters the LLM's context window at each step, has become a core skill for engineers building agents. A context engine is the infrastructure that makes context engineering possible at production scale.How a context engine sits between your data & your agentsThe context engine talks to both sides so your agent doesn't have to. On the data side, it connects to everything your agent might need: relational databases, document stores, vector indexes, internal APIs, event streams. It handles authentication, query translation, freshness, and access control once, instead of every agent re-implementing them.On the agent side, it speaks the language agents already understand: tools, schemas, and natural-language queries. The agent asks for "everything we know about customer X" or "the last five steps in this workflow," and gets back a clean, ranked payload, not a pile of raw rows from six different systems and the job of stitching them together. Build agents that remember, not agents that guess Redis Iris gives every agent fresh context and long-term memory. The three layers every production context engine should coverA working context engine has to do three things: get the right data (retrieval), remember what's happened (memory), and keep context both fast and current (caching & freshness). The next three sections walk through each.Layer 1: Retrieval & rankingRetrieval is the first layer to get right. Your agent needs to find the right documents, records, and facts in your data the moment it needs them, and rank them by what actually matters for the query.Most production systems use hybrid retrieval to do this: keyword search for exact terms like product codes, vector search for conceptually similar content, and a merged ranked list at the end. Retrieval also usually runs in two passes. Cast a wide net first with something fast and approximate, then re-rank to fit only the most relevant results into the token budget.But retrieval isn't just about documents. Agents also need structured context: who the user is, what plan they're on, which tickets they've opened, what their last order looked like. That data lives in your operational systems, not your vector index, and pulling it from a different place every time leads to agents that contradict themselves between turns.That's why context engines run retrieval and operational data through the same layer. Redis Search is built for exactly this: vector, full-text, and hybrid retrieval against the same data your app already uses, so your agent sees one consistent view instead of stitching together five.Layer 2: Memory & session stateRetrieval tells agents what's in your data. Memory tells agents what happened before. That distinction matters because LLMs themselves don't remember anything. Every call starts fresh: no user, no last turn, no decision from five steps ago. If your agent feels like it has memory, that's because something around the model is holding state and feeding it back in on every call. That something is the memory layer.Memory layers usually run on two timescales. Short-term working memory captures conversation context within a session, so the agent can refer back to what was said two turns ago. Long-term memory persists user preferences, past decisions, and high-signal facts across sessions, so the agent on Tuesday knows what the same user asked for on Friday.A memory layer also can't be passive. Dumping every message into a log won't cut it. Production memory systems actively distill conversations: extracting user profile information, summarizing chat history, and consolidating duplicate facts so the agent gets something useful back, not raw turns.Session state is a third, shorter-lived timeline. It tracks what the agent is currently doing across a multi-step workflow: which tools it's called, what those tools returned, and how far along the plan it is. Without this layer, agents start every turn from scratch, which compounds errors and erodes user trust.Redis Agent Memory handles all three timelines in one component: short-term working memory, long-term memory with vector retrieval, and session state. It also runs the distillation step automatically, summarizing sessions, promoting durable facts to long-term storage, and keeping it all retrievable by semantic similarity.Layer 3: Caching & data freshnessAfter retrieval and memory are in place, the remaining challenge is making context both fast and current. Semantic caching differs from traditional key-value databases. Instead of matching exact query strings, it uses vector similarity to identify semantically equivalent queries and serve cached responses. "What's the weather?" and "Tell me today's temperature" use different words but mean the same thing. At agent scale, parallel sub-agents or repeated sessions issue rephrased versions of the same question constantly.Every duplicate triggers a full retrieval-and-generation cycle without semantic caching in place. Cache hit rate becomes a production metric engineering teams should monitor alongside retrieval quality.On the freshness side, agents need data that reflects current state, not yesterday's batch export. When real-time data access is missing, retrieved context goes stale as indexed data diverges from the actual system state, and agents act on information that no longer reflects reality.Redis LangCache is a fully managed semantic caching service that catches rephrased duplicates and returns cached answers in milliseconds rather than running the full pipeline again. Redis Data Integration keeps your context fresh by syncing changes from operational databases like Postgres, MySQL, Oracle, and MongoDB into Redis in near real time, so what the agent retrieves matches what's actually in your systems right now.Fresh context, every call Redis Iris keeps agent data current so answers stay accurate.Why traditional RAG runs into limits at agent scaleMost RAG pipelines were designed around a simpler pattern: one question, one retrieval pass, one generation step, no memory between calls, no caching between calls. That works for chat over a fixed document set. It doesn't hold up when agents need to reason across multiple steps, share state, and reuse work.The three layers above name what's missing: iterative retrieval the model can guide, a memory substrate so agents don't start every turn from scratch, and semantic caching so duplicate queries don't trigger a full pipeline run each time.Stuffing more documents into the window doesn't fix this. When too many irrelevant or poorly structured documents land in context, the LLM gets worse at finding the right answer. One paper estimates that a 32k context length supports only about 10 to 15 effective interaction turns as tool responses accumulate. Researchers studying this have named four degradation modes that show up at scale:Context poisoning: errors or hallucinations that enter the context and get repeatedly referencedContext distraction: the model focusing on accumulated history over its trainingContext confusion: irrelevant content polluting responsesContext clash: conflicting information inside the windowSingle-pass RAG has no built-in defenses against any of them.What Redis adds to the context engine stackRedis is the real-time context engine for AI: sub-millisecond latency on many core in-memory operations, with vector search and semantic caching built into the same platform. It sits between raw data sources and the agent reasoning loops where these problems show up.Redis Iris packages retrieval, freshness, memory, and caching into one runtime built on top of Redis. Underneath it all is Redis Search, the fast layer that pulls structured, unstructured, and vector data. Iris is composed of five tools:Redis Search for retrievalRedis Agent Memory for memory and session stateRedis LangCache for semantic cachingRedis Data Integration for freshnessRedis Context Retriever for structured business data.Context Retriever targets a specific gap in the retrieval layer: getting agents to structured business data without relying on text-to-SQL. Devs define a semantic model of entities, fields, and relationships, and Context Retriever auto-generates Model Context Protocol (MCP) compatible tools that agents call to navigate that schema. Agents navigate business entities via defined interfaces instead of guessing at SQL. Currently in public preview.Supporting all of these tools is the underlying Redis Query Engine, which supports Hierarchical Navigable Small World (HNSW) and FLAT indexes for vector storage, k-nearest neighbor (kNN) and hybrid retrieval, and full-text search. In one published Redis benchmark on a billion-vector dataset, with 50 concurrent queries retrieving the top 100 neighbors under a specific HNSW configuration, Redis reported 90% precision at ~200ms median latency including round-trip time.Agents are only as smart as the data they can reach Redis Iris connects memory, live data, and retrieval in one place.
What is a context engine?
Learn what a context engine is, how it fits into agent architecture, where RAG falls short, and how Redis powers the context layer in production.
1,803 words~8 min read