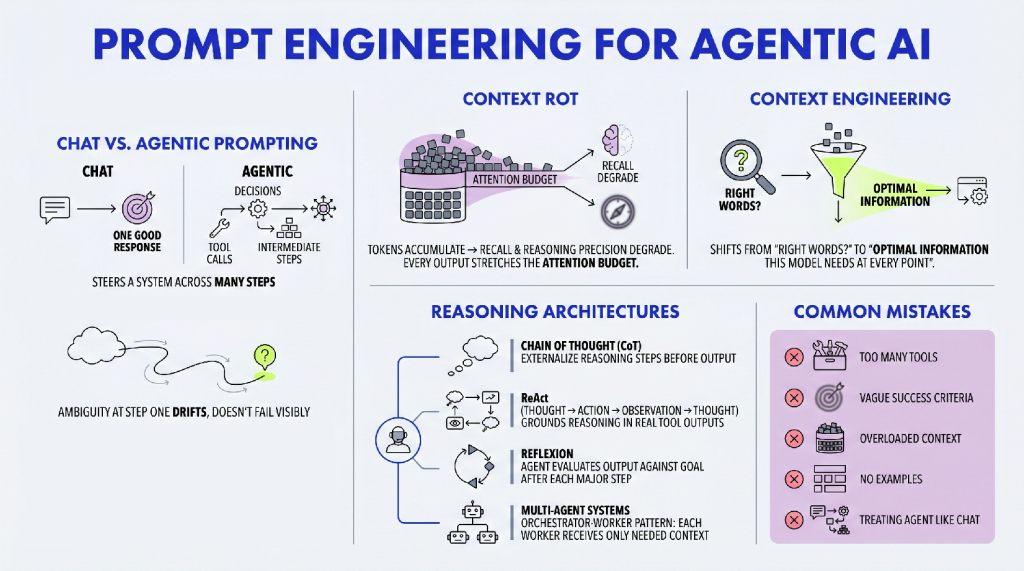
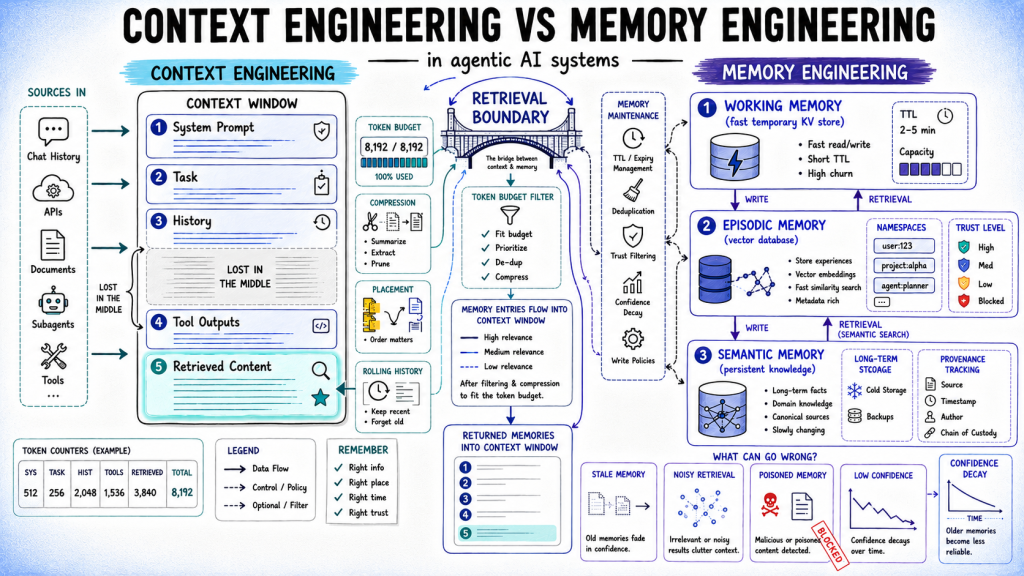
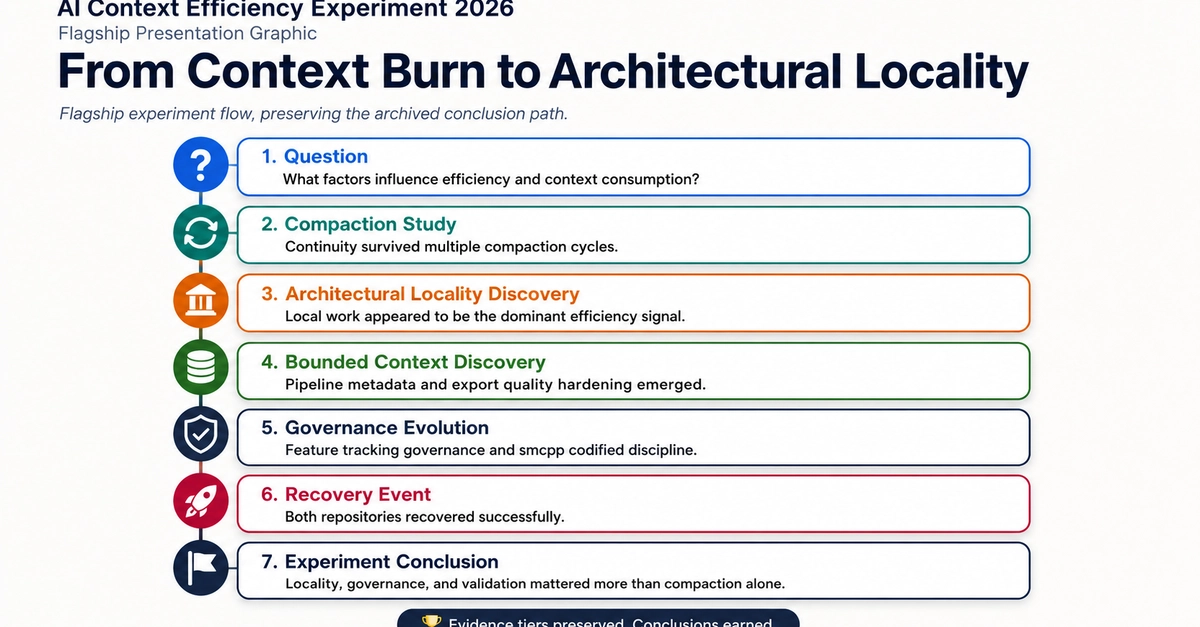
A team from Stanford, SambaNova, and UC Berkeley recently published the ACE paper - and it's the most substantive academic contribution to context engineering I've seen in a while. The core idea: give your AI agent a structured "playbook" that it maintains and refines itself, task by task. The result? A +10.6% performance improvement on agent benchmarks, and +8.6% on domain-specific finance reasoning, using a smaller open-source model that matched top-ranked production agents.
ACE works through three components - a Generator, a Reflector, and a Curator - that mirror how humans actually learn: attempt, reflect, consolidate. The Curator's key trick is issuing small, surgical edits to the playbook rather than rewriting it wholesale. That single design choice is what prevents the context degradation most agents suffer silently.
Here's the honest caveat: you probably shouldn't run out and implement this today. But you should understand what it proves, because the principles transfer directly to how you work with AI agents right now.
The Problem ACE Is Trying to Solve
If you've spent time building or using AI agents, you've encountered two failure modes that nobody talks about clearly enough.