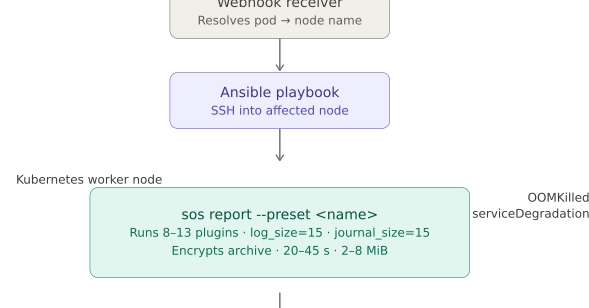
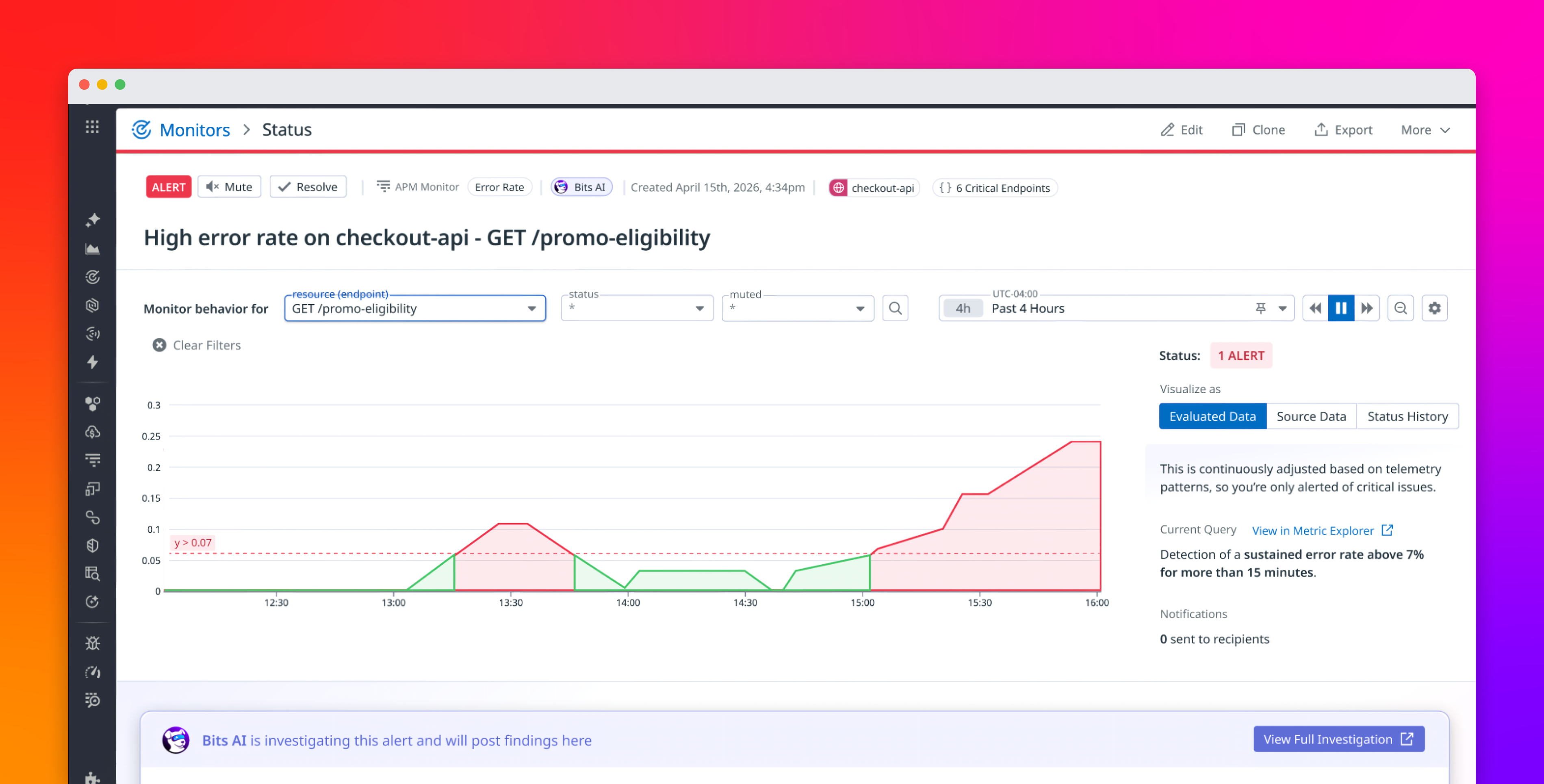
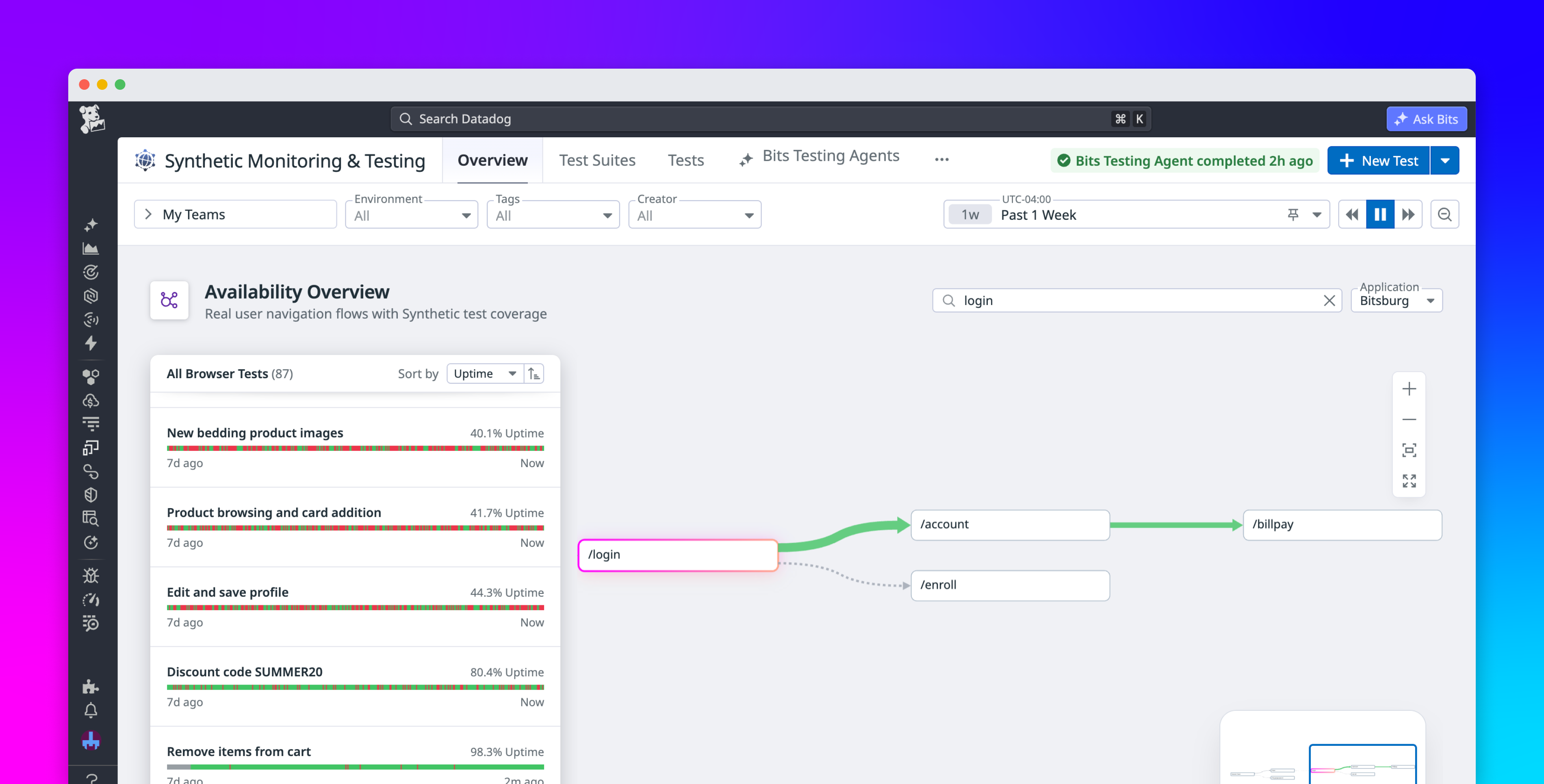
Alert fatigue and blind spots develop together. Monitoring stacks that generate noise while missing critical issues may have incomplete coverage or poorly configured alerts. As they grow reactively and without structured coverage assessment, both issues worsen. Teams will often add monitors when something breaks and tune thresholds when alerts become unbearable, but rarely audit their overall setup to see if it works.
To develop a healthy monitoring stack, teams need to get two things right: coverage and quality.
Assess monitoring coverage across your stack
Effective coverage is not the same as monitor quantity. What matters is whether you’re detecting failure modes across each layer of your system. Those layers fall into a rough priority order. Gaps in lower layers are often silent and tend to surface once Layer 1 or 2 starts degrading. Visibility at all layers matters even if alerting thresholds differ.
Layer 1 is the highest-priority layer. If it has no alerts, users will report outages before monitors do.Layer 2 is where most teams have some coverage, but often with poorly configured thresholds.Layer 3 tends to be under-monitored, even though dependency failures are a leading cause of service degradation.Layer 4 covers signals that should primarily drive tickets instead of alerts, unless they directly correlate with user impact. For example, memory usage trending steadily upward over hours may indicate a leak heading toward an out-of-memory crash. That’s worth an alert, but a brief CPU spike during a deployment that resolves within minutes is not. AI-assisted tools like Bits AI SRE can help make these judgment calls automatically, flagging infrastructure signals that correlate with user impact without manual threshold tuning.