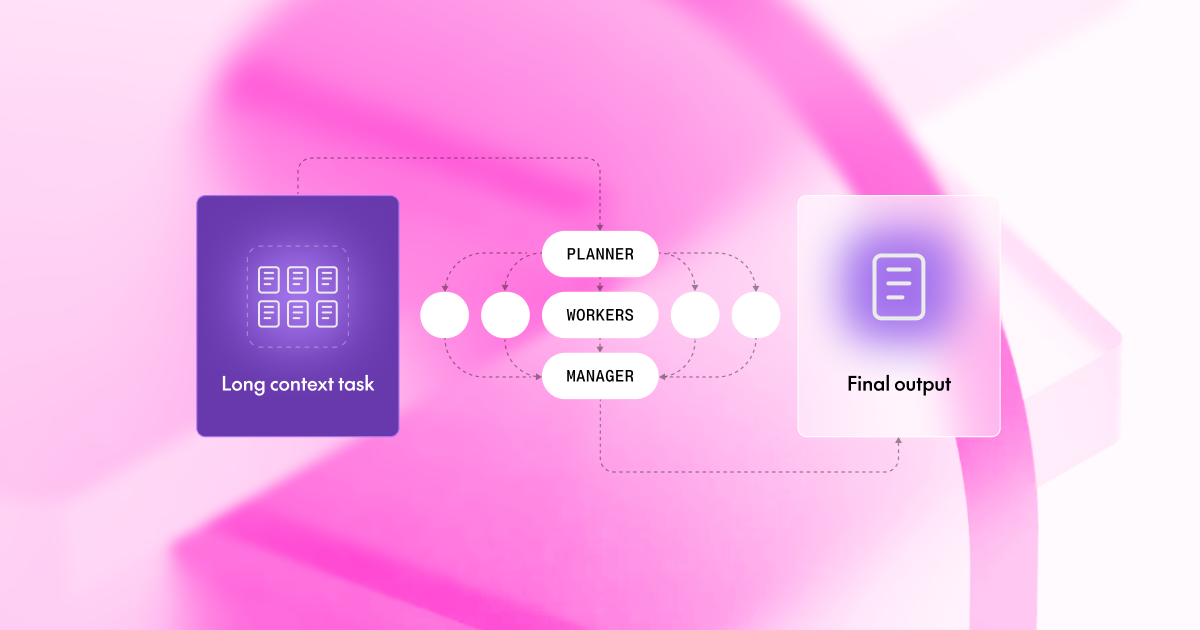
When you analyze documents that span millions of characters, you hit the context window barrier and even the largest context windows fall short. Your model either rejects the input or produces answers based on incomplete information. How do you reason over documents that don’t fit?
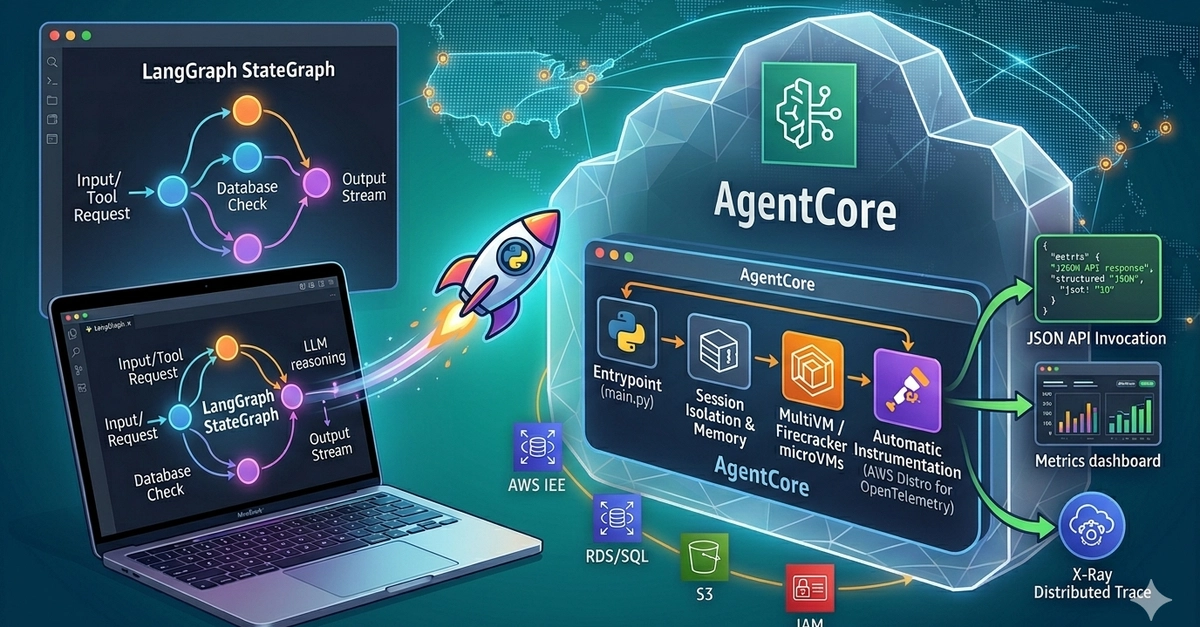
In this post, you will learn how to implement Recursive Language Models (RLM) using Amazon Bedrock AgentCore Code Interpreter and the Strands Agents SDK. By the end, you will know how to:
Process documents of varying lengths, with no upper bound on context size.
Use Bedrock AgentCore Code Interpreter as persistent working memory for iterative document analysis.
Orchestrate sub-large language model (sub-LLM) calls from within a sandboxed Python environment to analyze specific document sections.