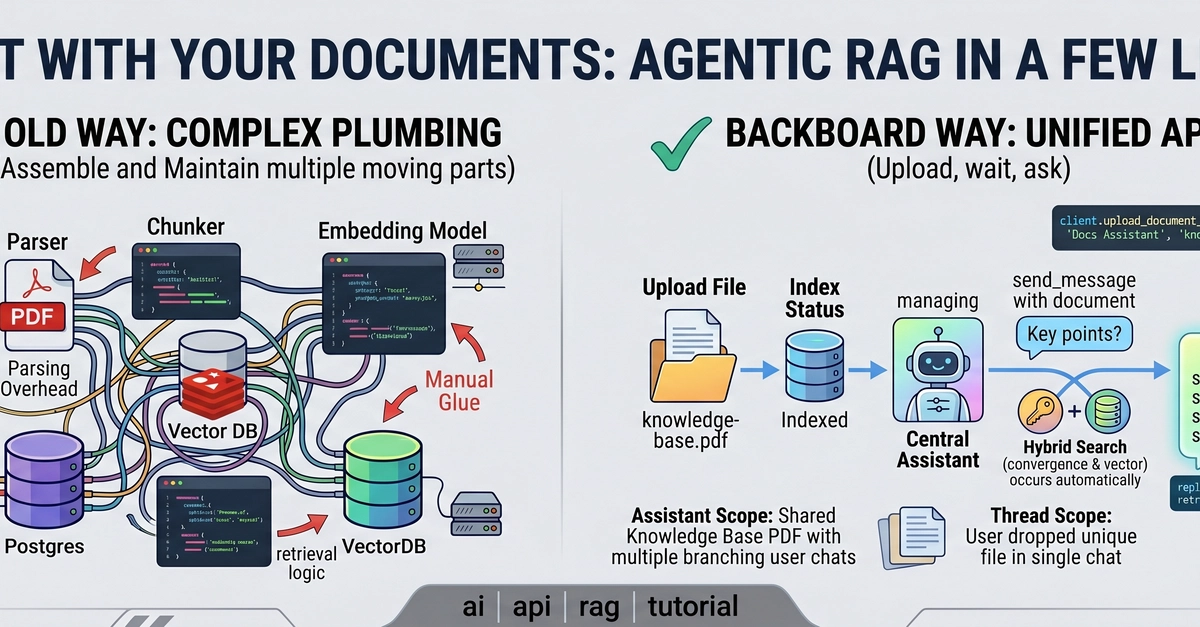
Most AI document processing relies heavily on Retrieval-Augmented Generation (RAG). We chunk data into tiny pieces, vectorize it, and stitch the summaries together. RAG is excellent for finding a needle in a haystack, but it is fundamentally flawed when you need the model to understand the entire haystack at once.
With the release of Gemma 4, specifically the native 128K context window, we finally have the tools to move away from aggressive chunking.
In this post, I’ll break down why long-context local models change how we design AI pipelines, examine the architectural differences between the Gemma 4 variants, and share a case study of how I utilized the 31B Dense model to process massive, unbroken log files locally.
The Problem: Chunking Destroys Narrative Coherence
Imagine an Operational Command Center (OCC) monitoring a multi-tenant Kubernetes deployment. A massive cascading failure occurs, generating 200 interconnected infrastructure alerts—Kafka backlogs, CPU spikes, and database deadlocks.