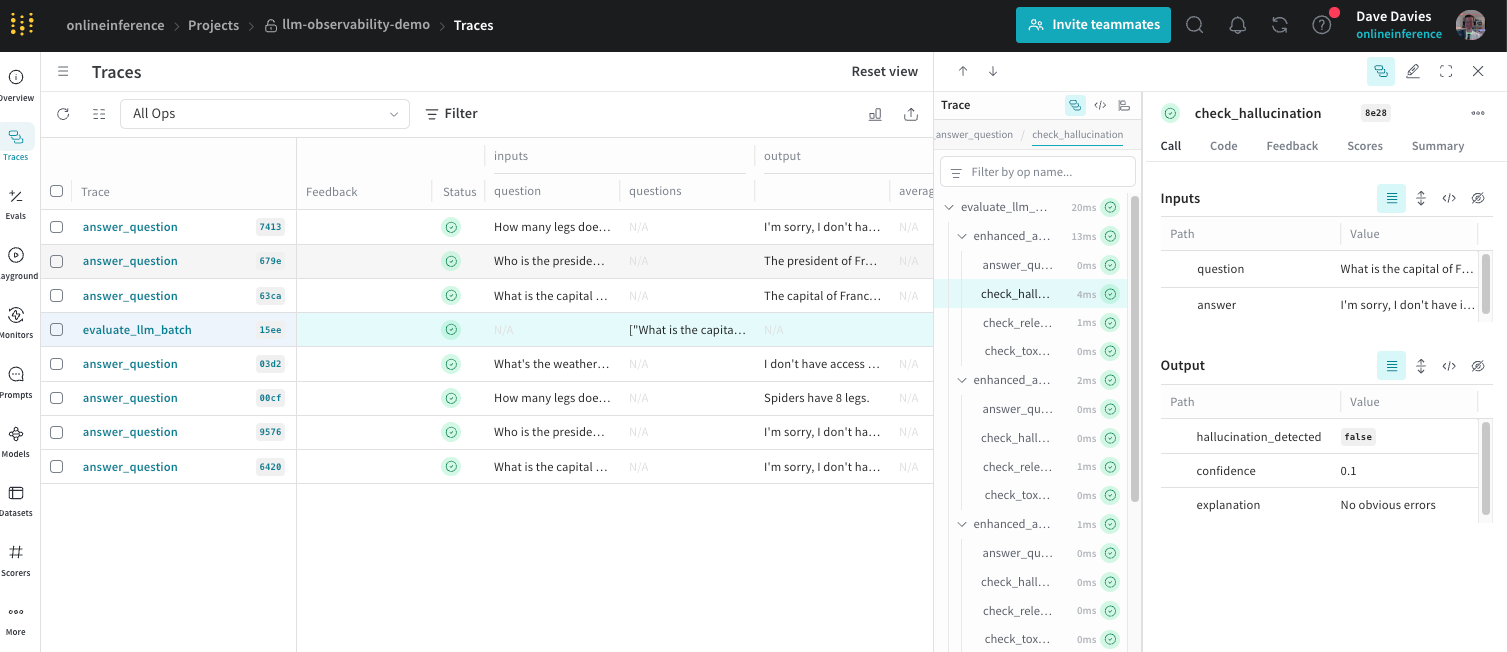
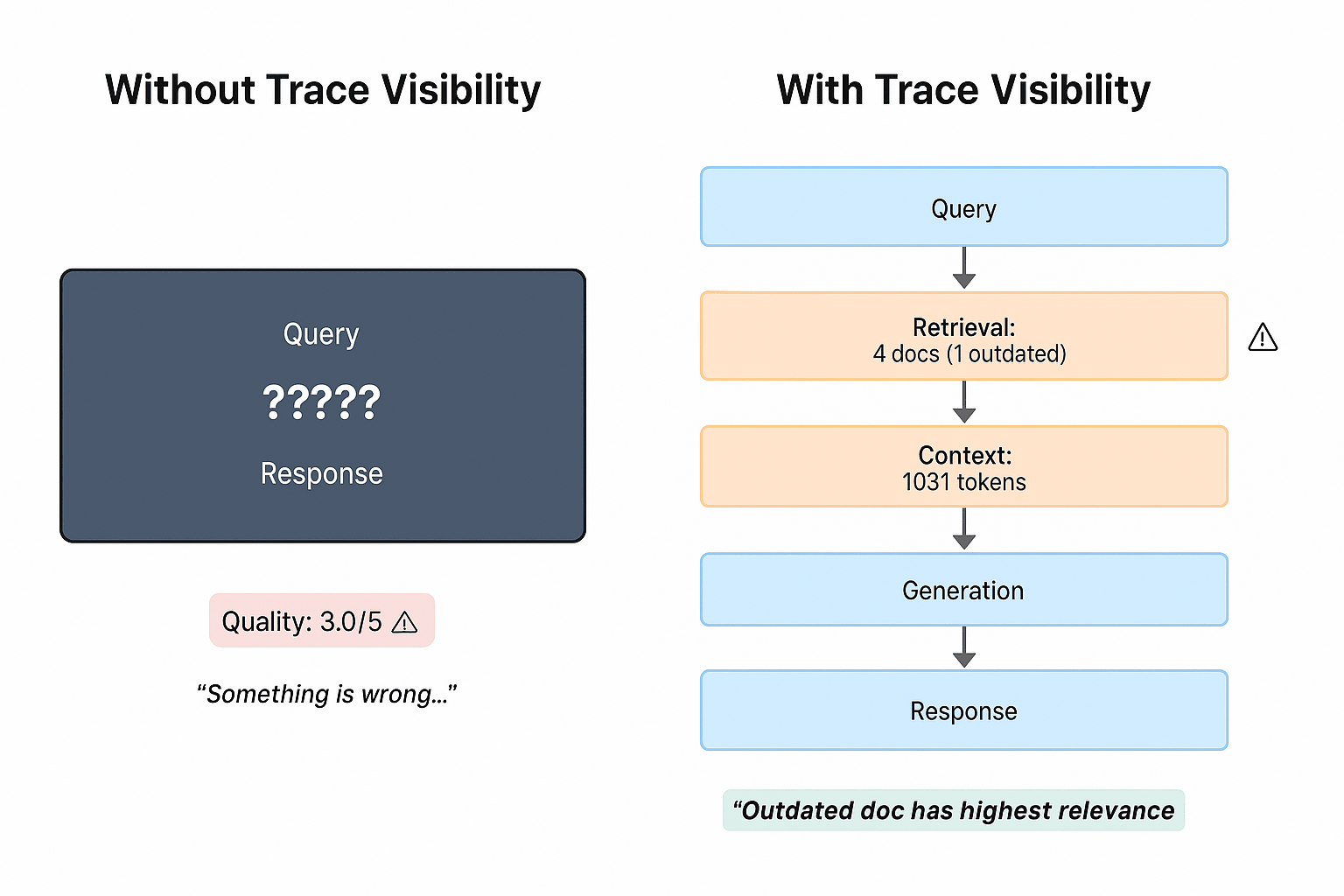
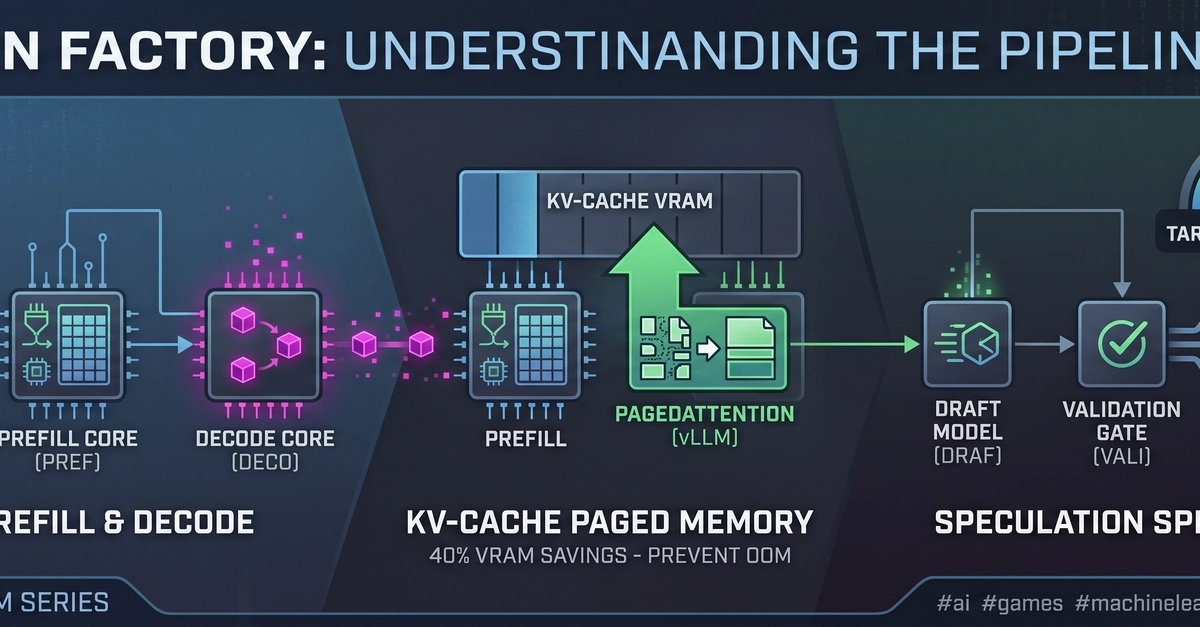
Running large language model inference servers in production exposes gaps that neither stock Prometheus dashboards nor the official documentation of vLLM or TGI cover completely. This article maps the layers that matter, names the exact signals to scrape and flags the traps most teams only hit after real traffic arrives.
Audience: SREs, ML platform engineers and observability engineers who operate or are about to operate vLLM or TGI on GPUs.
Why LLM serving breaks standard observability
A model server is not a regular web service. Four properties invalidate the usual playbook.
Latency is not scalar. Time to first token (TTFT), inter-token latency (ITL) and end-to-end latency tell three different stories. Optimizing one usually degrades another. Prefill-bound workloads (long prompts, short outputs) and decode-bound workloads (chat, agents, RAG) have inverse profiles. A single p99 number is meaningless without saying which latency it refers to and what input distribution produced it.