Back to Articles
For a long time, "scaling" in foundation models mostly meant one thing: spend more compute on pre-training and capabilities rise. That intuition was supported by empirical work such as Kaplan et al. (2020), which reported predictable power-law trends in loss as you scale model parameters, dataset size, and training compute. In practice, these trends justified sustained investment in large-scale accelerator capacity and the surrounding distributed infrastructure needed to keep it efficiently utilized.
But the frontier has evolved—and scaling is no longer a single curve. NVIDIA's "from one to three scaling laws" framing usefully emphasizes that, beyond pre-training, performance increasingly scales through post-training (e.g., supervised fine-tuning (SFT) and reinforcement learning (RL)-based methods) and through test-time compute ("long thinking," search/verification, multi-sample strategies).
Figure: Adapted from "AI's Three Scaling Laws, Explained" (NVIDIA Blog).
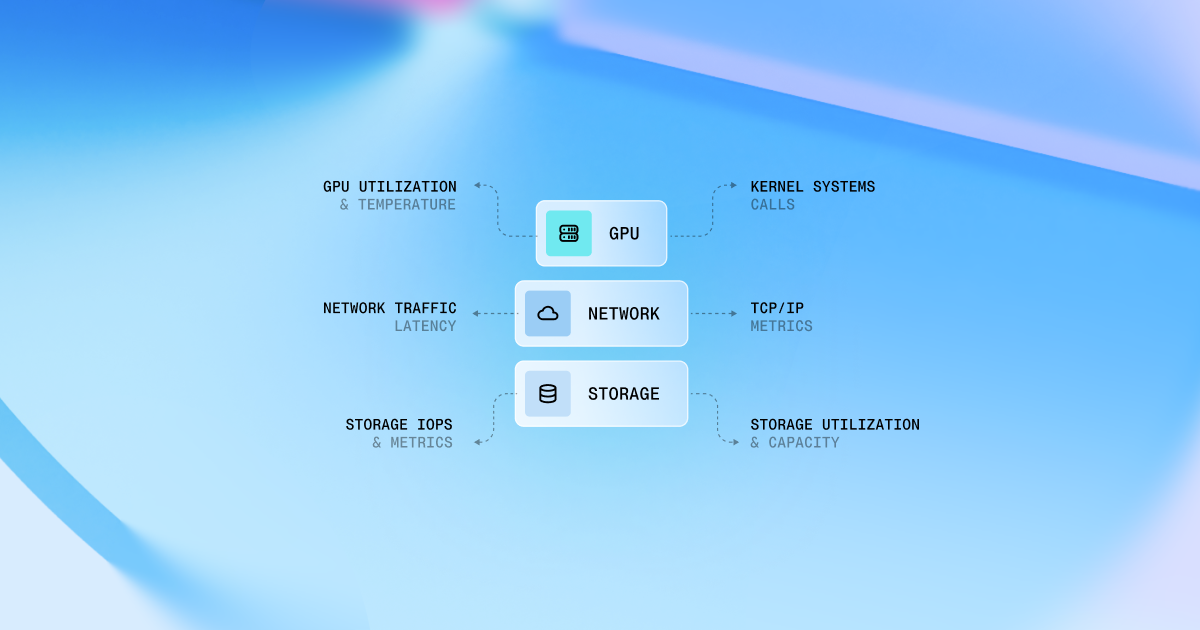
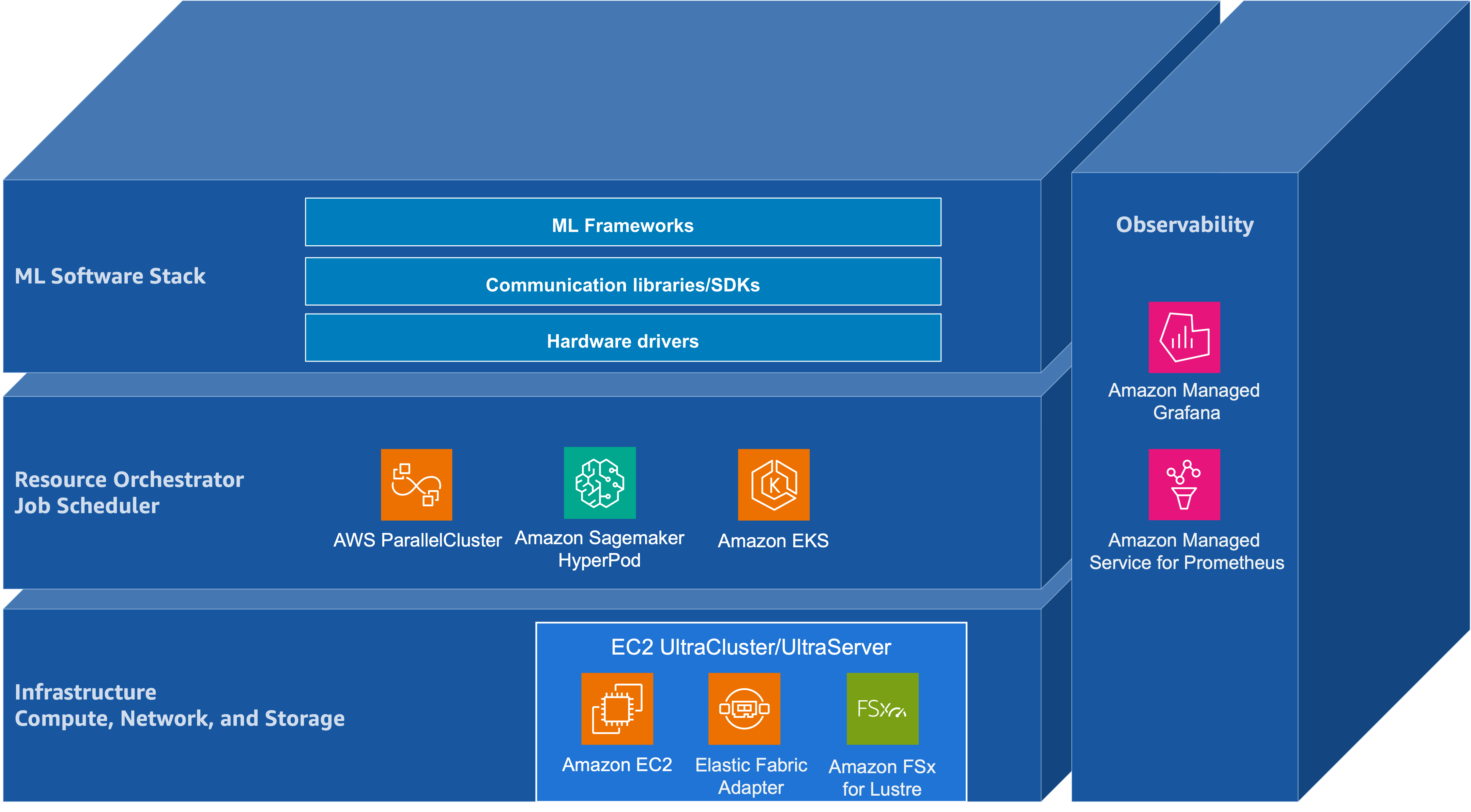
Taken together, these scaling regimes push the foundation-model lifecycle—pre-training, post-training, and inference—toward convergent infrastructure requirements: tightly coupled accelerator compute, a high-bandwidth low-latency network, and a distributed storage backend. They also raise the importance of orchestration for resource management, and of application- and hardware-level observability to maintain cluster health and diagnose performance pathologies at scale.