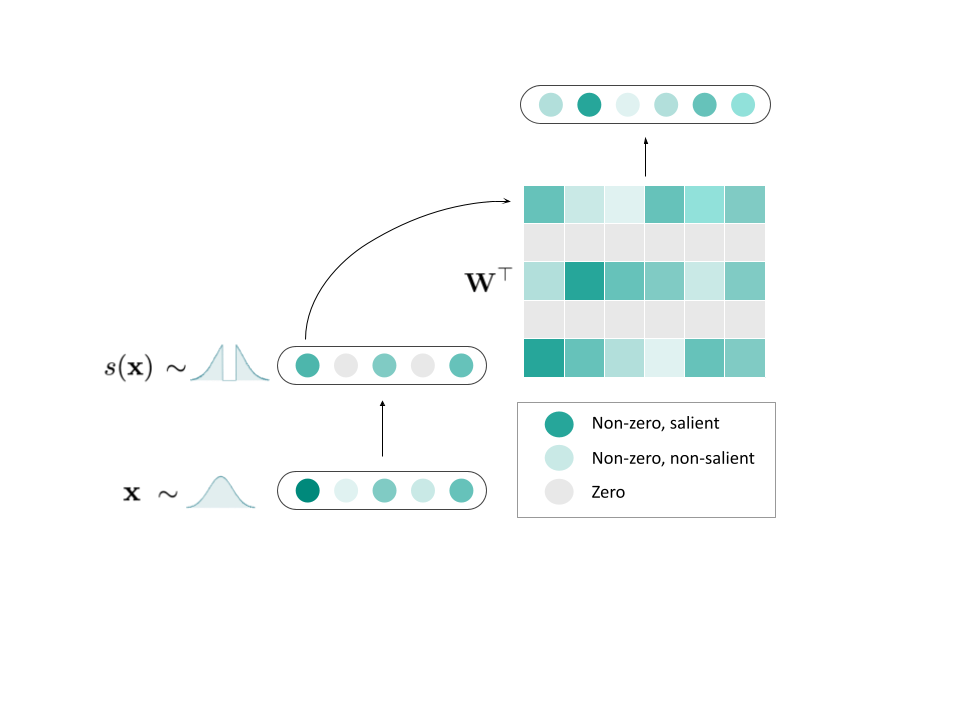
The two-phase training technique — validated across four model scales from 270M to 10B parameters — modifies only the training loop, leaving the inference-time architecture completely untouched.
Pre-training large language models is expensive enough that even modest efficiency improvements can translate into meaningful cost and time savings. Nous Research is releasing Token Superposition Training (TST), a method that substantially reduces pre-training wall-clock time at fixed compute without touching the model architecture, optimizer, tokenizer, parallelism strategy, or training data.
At the 10B-A1B mixture-of-experts scale, TST reaches a lower final training loss than a matched-FLOPs baseline while consuming 4,768 B200-GPU-hours versus the baseline’s 12,311 — roughly a 2.5x reduction in total pre-training time.
Modern LLM pre-training is heavily data-driven. Recent training regimes routinely overtrain well beyond compute-optimal estimates, and raw text throughput. How much data a model can process per FLOP has become a key lever. Subword tokenizers like BPE already improve throughput by compressing sequences; and the research suggests much of the BPE advantage over byte-level models comes simply from shorter sequences, which means the model sees more text per unit of compute.