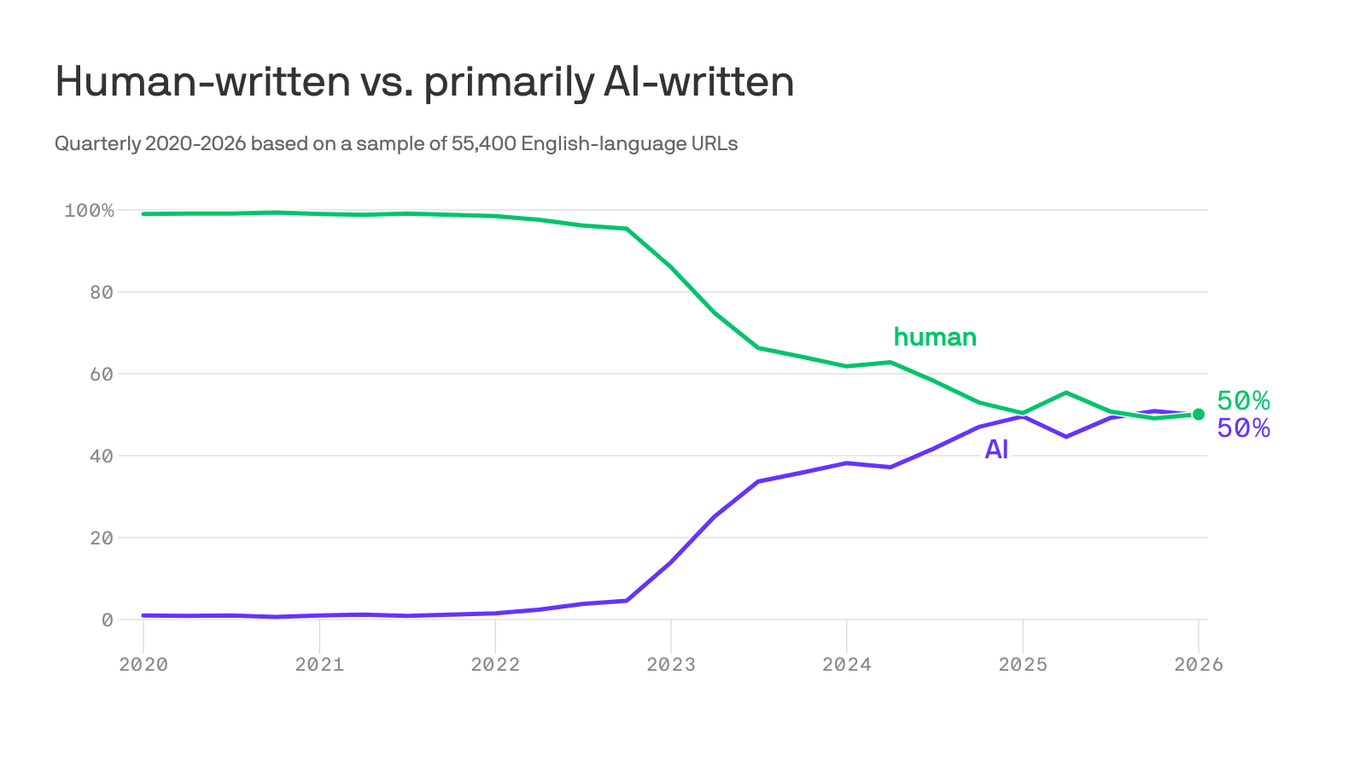
There’s a theory that a rising tide of LLM-generated nonsense will eventually drown both LLMs themselves and the internet as a whole. The idea goes like this: The first generation of LLMs is trained entirely on “real” material: the Gutenberg project, 4chan, that one article from Thought Catalog a decade ago, and everything in between. But as the output of those LLMs spreads across the internet, it also becomes part of the training data of future LLMs—and much of it is bullshit. As a result, the quality of newer LLMs’ training data is inferior to that of their predecessors—and by extension, so is their output. And as that output accumulates on the internet, it becomes part of future training data, and the cycle continues. With each passing day, the proportion of the internet that’s low-quality LLM-generated bullshit increases, until eventually all that’s left to train LLMs is the gibberish created by their predecessors. The end result is a sort of RAM-hoovering, water-guzzling, bullshit-munching ouroboros, an unholy circular undulant with Jensen Huang’s face at one end and Sam Altman’s at the other, slowly human-centipeding both itself and the internet into oblivion. If humanity hasn’t set fire to the planet by that point, then we start a new internet, hopefully with lessons learned along the way.
A Wikipedia Clone Built on AI Hallucinations Is Here to Hasten Along the Death of the Internet
If we're all going to drown in a sea of nonsense, it might as well at least be funny.
628 words~3 min read