A team of researchers from Meta, Stanford University, and the University of Washington have introduced three new methods that substantially accelerate generation in the Byte Latent Transformer (BLT) — a language model architecture that operates directly on raw bytes instead of tokens.
To understand what this new research solves, you need to understand the tradeoff at the center of byte-level language modeling.
Most language models today work on tokens — chunks of text produced by subword tokenizers like byte-pair encoding (BPE). A token typically represents several characters or even a whole word. While this is efficient, tokenization comes with known downsides: sensitivity to input noise, poor handling of multilingual text, weak character-level understanding, and fragility on structured inputs like code and numbers.
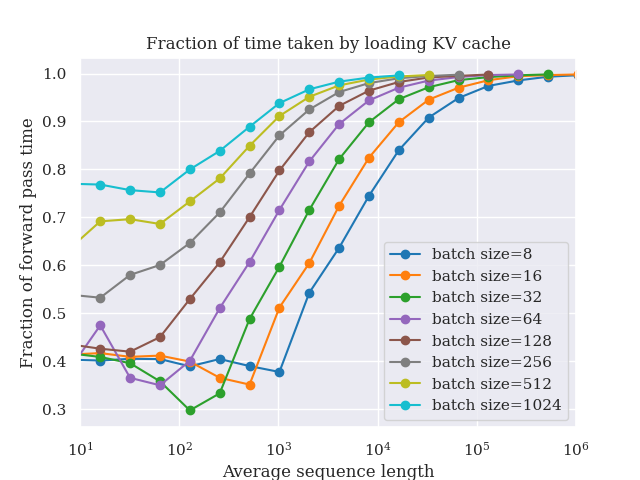
Byte-level models sidestep all of this by operating directly on raw bytes — the lowest-level representation of text. The Byte Latent Transformer (BLT) was a major step forward: it matched the performance of tokenization-based models at scale by grouping bytes dynamically into variable-length patches using an entropy-based segmentation strategy. High-entropy (harder-to-predict) regions get shorter patches; more predictable spans get longer ones. The bulk of computation runs over latent token representations, not raw bytes — using three components: a local encoder, a large global Transformer, and a local decoder — with an average patch size of 4 bytes and a maximum of 8.