Home
Storia in 1 fonti
A Better LLM Judge? The Rubric Made My Small Model Worse
Part 3 of an eval series. I tried to fix a 43%-agreement LLM judge two ways — a bigger model (DeepSeek & Qwen via OpenRouter) and a real anchored rubric — in a 2x2 against human votes. The rubric helped the big model and HURT the small one. A good rubric needs a model capable of following it.
Raccontata da dev.to
dev.to
Timeline cronologica
- ·

LLM-as-a-Judge: I Built One From Scratch, Then Checked It Against Humans
Part 2 of an eval series. A 15-line LLM judge, scored against real Chatbot Arena human votes. It agreed with people on just 43% of pairs, tied a third of them, parked every score…
- ·
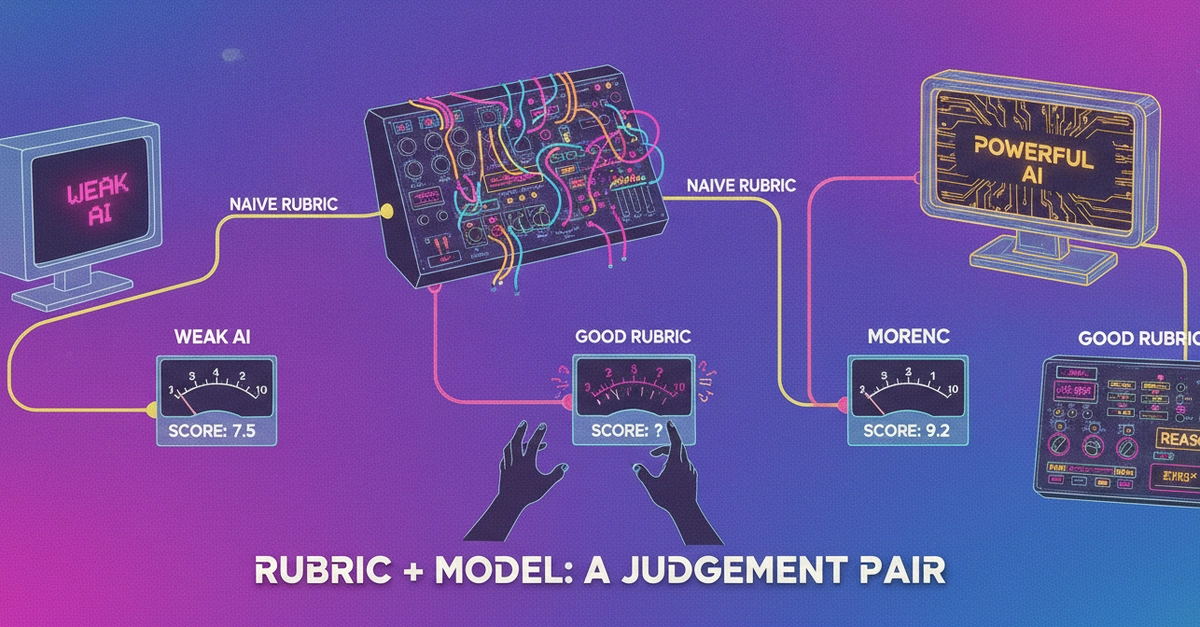
A Better LLM Judge? The Rubric Made My Small Model Worse
Part 3 of an eval series. I tried to fix a 43%-agreement LLM judge two ways — a bigger model (DeepSeek & Qwen via OpenRouter) and a real anchored rubric — in a 2x2 against human…