HomeAI · summaries
Storia in 2 fonti
MiniMax teases M3 model with new sparse attention mechanism, 15.6X long-context response speed boost
It directly solves the exact bottleneck that normally makes AI chatbots freeze or stutter when handling massive amounts of information.
Confronto fonti
2 prospettive sulla stessa storiaTimeline cronologica
- ·
venturebeat.com

MiniMax teases M3 model with new sparse attention mechanism, 15.6X long-context response speed boost
It directly solves the exact bottleneck that normally makes AI chatbots freeze or stutter when handling massive amounts of information.
- ·
cryptobriefing.com
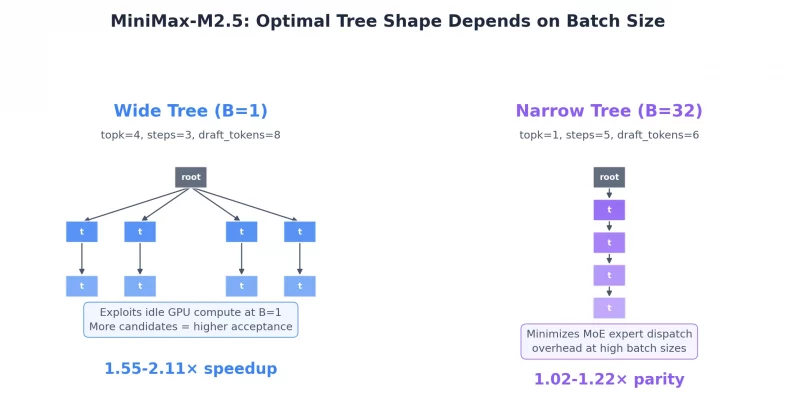
MiniMax teases M3 model with 15.6x faster decoding speed boost
MiniMax teases its M3 model with 15.6x faster decoding and 9.7x faster prefill using a new sparse attention architecture, with implications for decentralized AI.