MiniMax, the Shanghai-based AI lab backed by Tencent, Alibaba, and miHoYo, just dropped a technical report on its M2 model series. Buried inside was a tease of its next-generation M3 model, which the company claims achieves a 15.6x faster decoding speed and 9.7x faster prefill speed compared to M2 when processing 1M-token contexts.
What MiniMax actually built
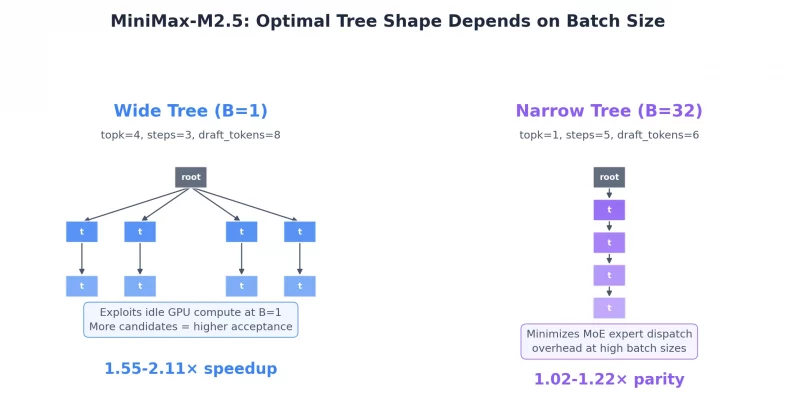
The secret sauce behind the M3 teaser is something MiniMax calls MiniMax Sparse Attention, or MSA. It’s built on a technique called GQA-driven dynamic block selection. Instead of having the model pay attention to every single piece of information in a massive context window, MSA intelligently picks which blocks of data actually matter for a given query. The result is dramatically less compute for roughly the same quality of output.
MiniMax claims the M3 model maintains output quality comparable to M2 despite these massive speed improvements.
The technical report itself covers the engineering innovations across the entire M2 lineup: M2, M2.5, and M2.7.








