Home
Storia in 1 fonti
Tabby with Replicas and a Reverse Proxy | Tabby AI coding assistant
Tabby operates as a single process, typically utilizing resources from a single GPU.This setup is usually sufficient for a team of ~50 engineers. However, if you wish to scale this for a larger team, you'll need to harness compute resources from multiple GPUs. One approach to achieve this is by creating additional replicas of the Tabby service and employing a reverse proxy to distribute traffic among these replicas.This guide assumes that you have a Linux machine with Docker, CUDA drivers, and the nvidia-container-toolkit already installed.Let's dive in!Creating the CaddyfileBefore configuring our services, we need to create a Caddyfile that will define how Caddy should handle incoming requests and reverse proxy them to Tabby:http://*:8080 {
Raccontata da tabbyml.com
tabbyml.com
Timeline cronologica
- ·
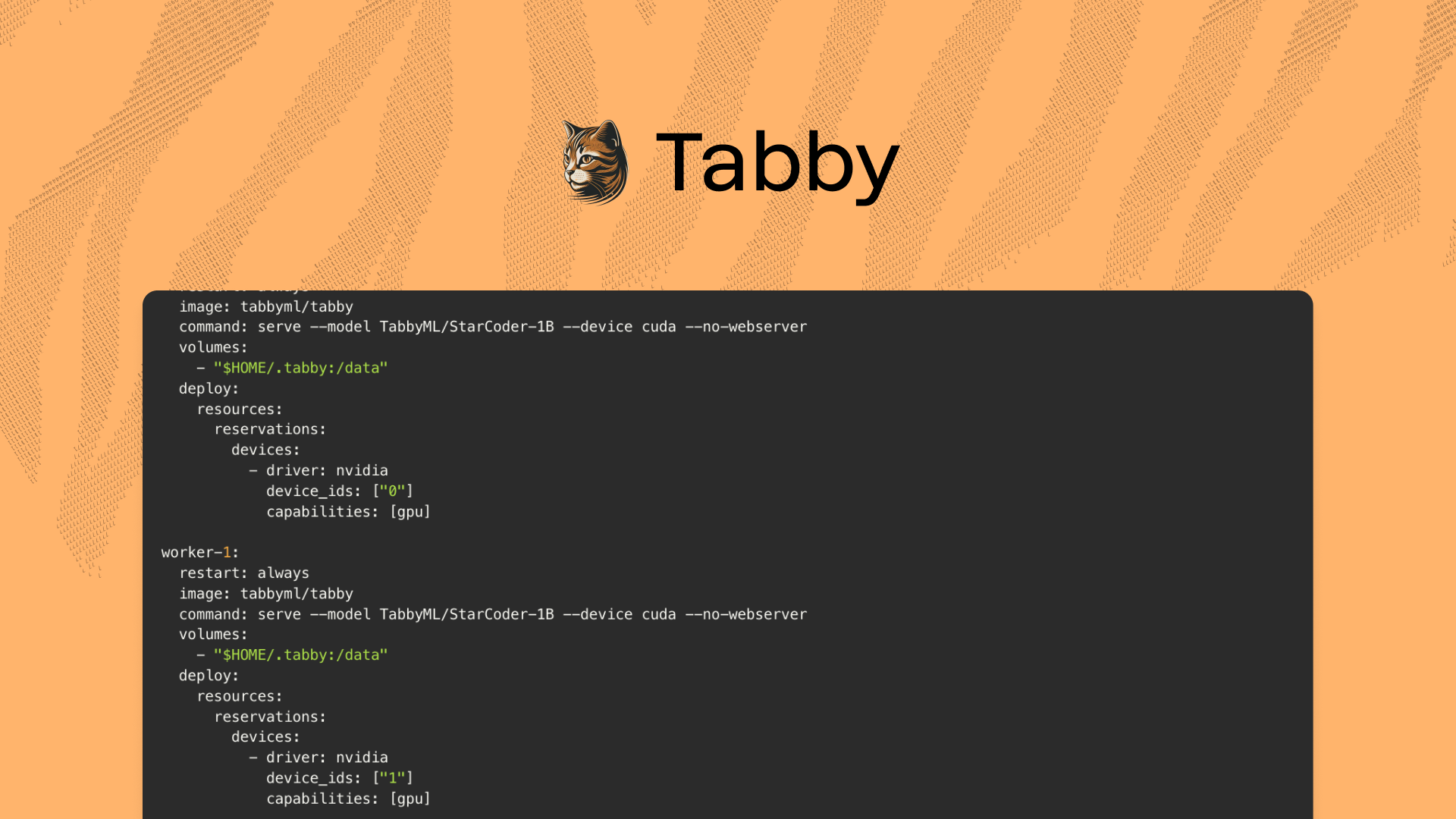
Tabby with Replicas and a Reverse Proxy | Tabby AI coding assistant
Tabby operates as a single process, typically utilizing resources from a single GPU.This setup is usually sufficient for a team of ~50 engineers. However, if you wish to scale…
- ·

Deploying a Tabby Instance in Hugging Face Spaces | Tabby AI coding assistant
Hugging Face Spaces offers an easy-to-use Nvidia GPU hosting runtime, allowing anyone to host their machine learning models or AI applications.In this blog post, we are going to…
- ·
Running Tabby Locally with AMD ROCm | Tabby AI coding assistant
infoTabby's ROCm support is currently only in our nightly builds. It will become stable in version 0.9.For those using (compatible) AMD graphics cards, you can now run Tabby…