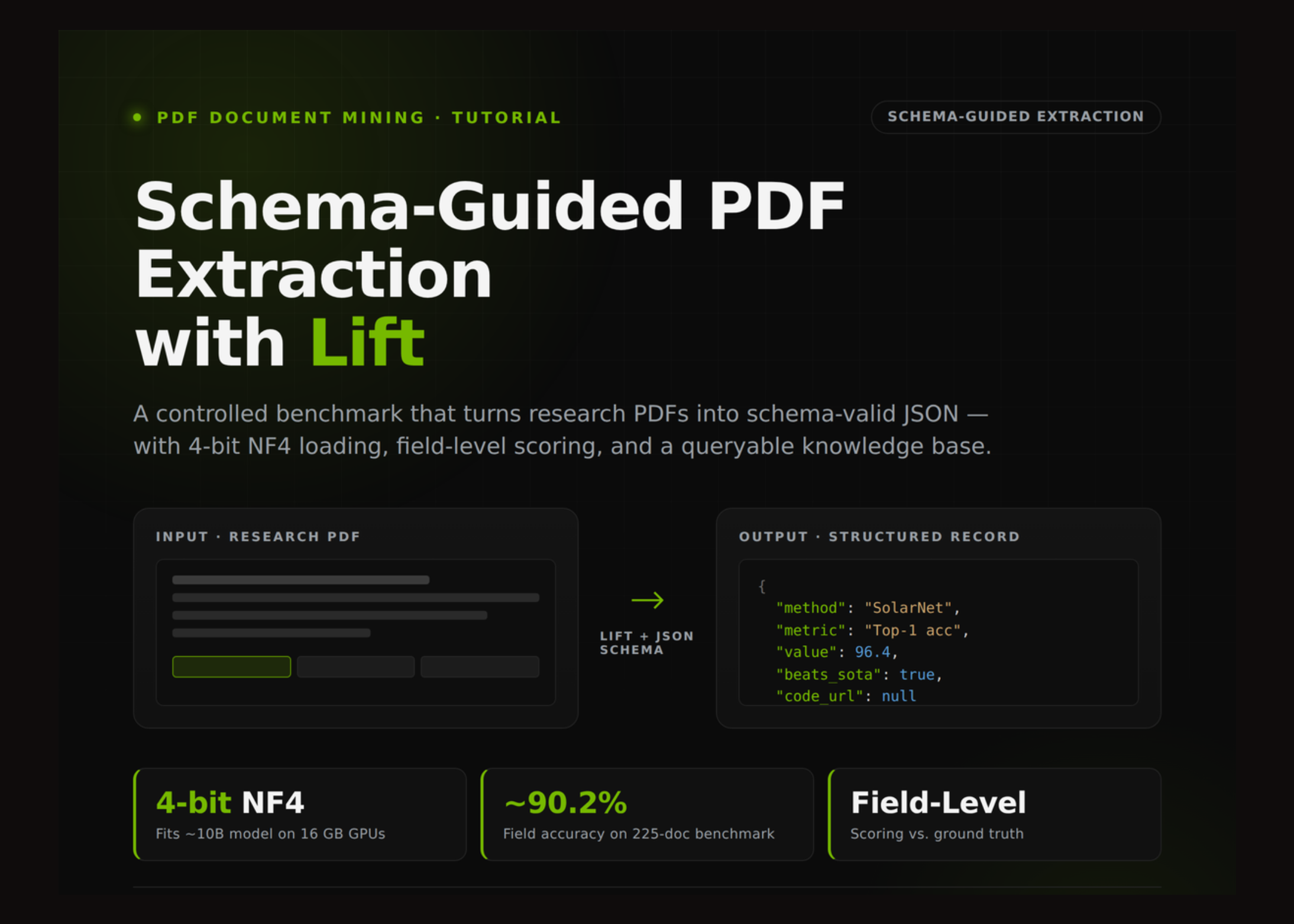
In this tutorial, we build an end-to-end accounts-payable extraction pipeline with lift-pdf, using synthetic invoice PDFs as controlled test documents and a structured JSON schema as the target output format. Instead of treating invoice parsing as a simple OCR task, we frame it as schema-guided document understanding: we generate realistic invoices, define fields such as vendor identity, billing party, PO number, line items, tax, total amount, balance due, and payment status, and then ask the model to extract those values directly from the rendered PDF layout. We also include practical extraction traps that appear in real finance workflows, such as distinguishing bill-to from ship-to, separating subtotal from after-tax total, returning null for absent values, and correctly marking partially paid invoices as unpaid when a balance remains. Through GPU-aware model loading, optional 4-bit quantization, PDF generation and extraction, scoring, and ledger construction, we turn this tutorial into a compact yet realistic demonstration of document intelligence for invoice mining.
N_DOCS = 3
FORCE_FULL_PRECISION = False
FORCE_4BIT = False
SHOW_FIRST_PAGE = True