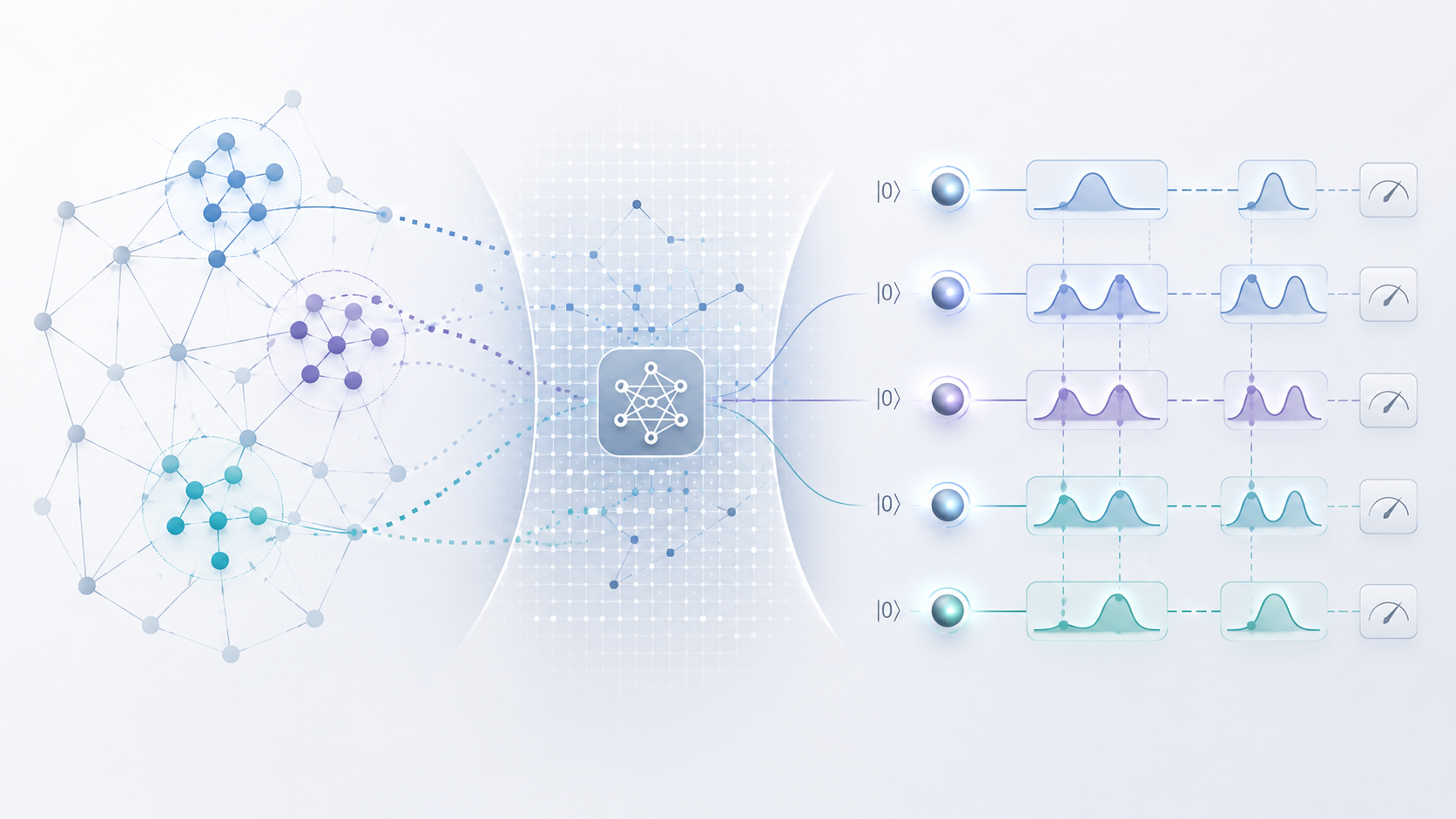
Sophisticated AI models tend to require a lot of memory and take up a lot of storage space. One of the ways to reduce that footprint involves a process called quantization, which changes how model weights are represented and stored. But quantization has its drawbacks. Andrés Mac Allister, CEO and founder of The SEMQ Group, believes there's another way to make machine learning more efficient and less resource intensive. Instead of compressing model weights (specifically embeddings), he contends you can separate the semantics (the meaning) from how that meaning is represented.Model weights, including embeddings (which map tokens to vectors), are the numbers in a machine learning model that determine how strongly one piece of information relates to another. Taken all together, they reflect learned behavior.
These parameters are commonly represented in Full-Precision (FP32), which requires 4 bytes per parameter. A 7B parameter model at FP32 would need about 28 GB of disk space and memory.
To save space, the model might be quantized at FP16/BF16, which requires 2 bytes per parameter. The resulting model would need about 14 GB of disk space and memory. And there are smaller quantization options like FP8, INT8/Q8, Q6, Q5, Q4, Q3, and Q2, each of which reduces the storage and memory footprint while also reducing precision – the answers get worse.SEMQ stands for Symbolic Embedding Multi-Quantization. As described in a paper published earlier this year, SEMQ "replaces raw vectors with fixed-dimensional symbolic structures that preserve relational properties, such as relative similarity ordering and neighborhood structure, while decoupling representation from metrics, indexing, and execution semantics."Essentially, Mac Allister has devised a way to construct a semantic abstraction layer that decouples the meaning captured in embeddings – vectors representing data – from the way that data is represented. The operative idea is that semantic relationships depend primarily on the relative orientation of embedding vectors, so the absolute magnitude of those vectors becomes less important to preserve. That's less data to store.The potential impact to businesses running AI workloads depends on the portion of infrastructure costs attributable to semantic state."An embedding is usually represented as a long vector of floating-point numbers," Mac Allister explained in an email to The Register. "In conventional embedding systems, semantic state is typically stored as a sequence of high-precision numerical coordinates. Those coordinates jointly encode both magnitude and direction in the embedding space.