Engineering teams that manage high-volume log sources, such as content delivery network (CDN) edges, streaming platforms, and authentication systems, often have to make a difficult retention tradeoff. Indexing every event keeps logs searchable during investigations, audits, and postmortems, but it can make long-term retention expensive. Archiving those logs in object storage helps control costs, but it often moves historical investigations into a separate query environment, such as Amazon S3 with Athena, a secondary data lake, or a dedicated CDN analytics tool. This fragmentation forces teams to work with a secondary query language, access control model, and operational context.
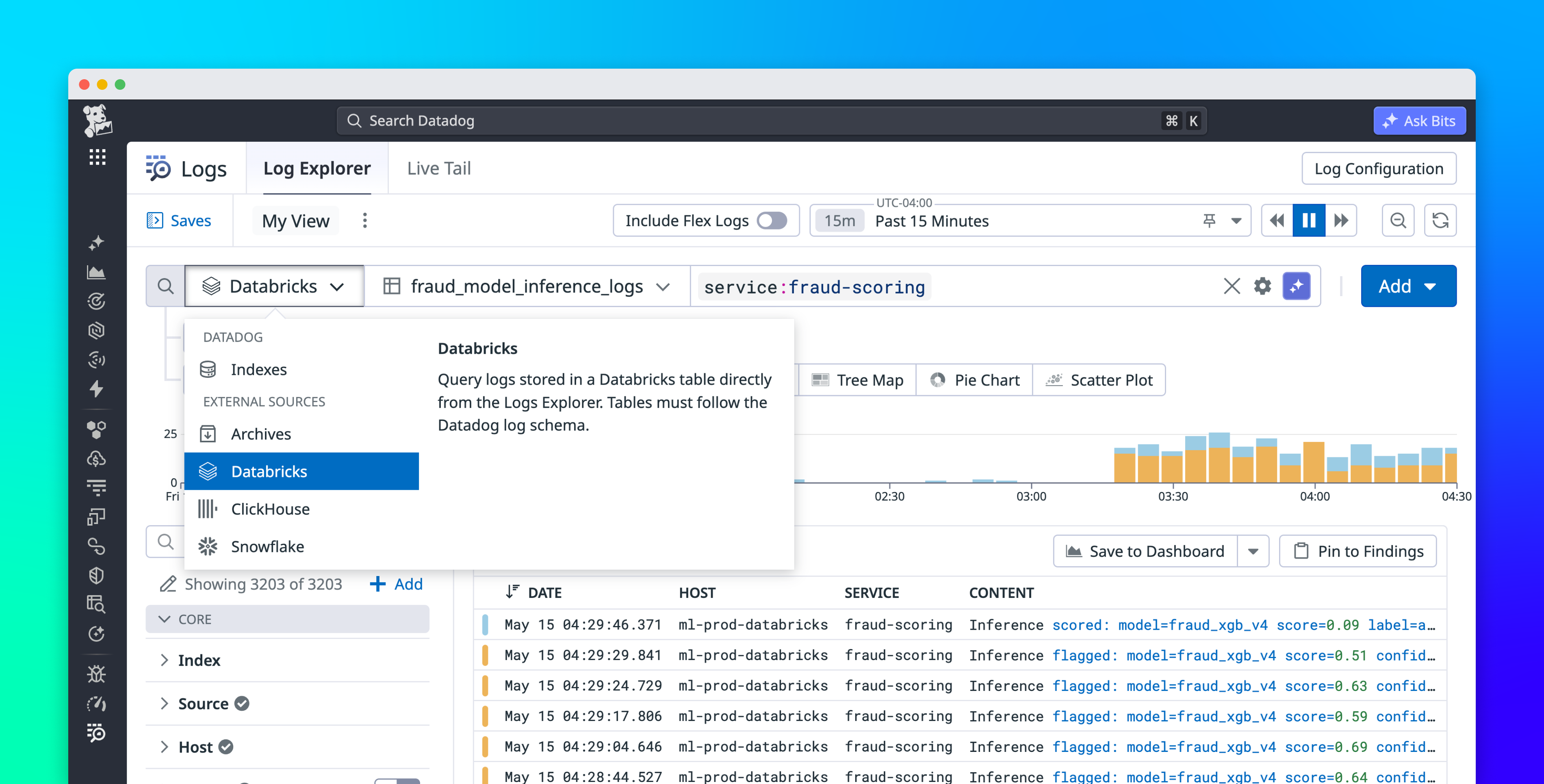
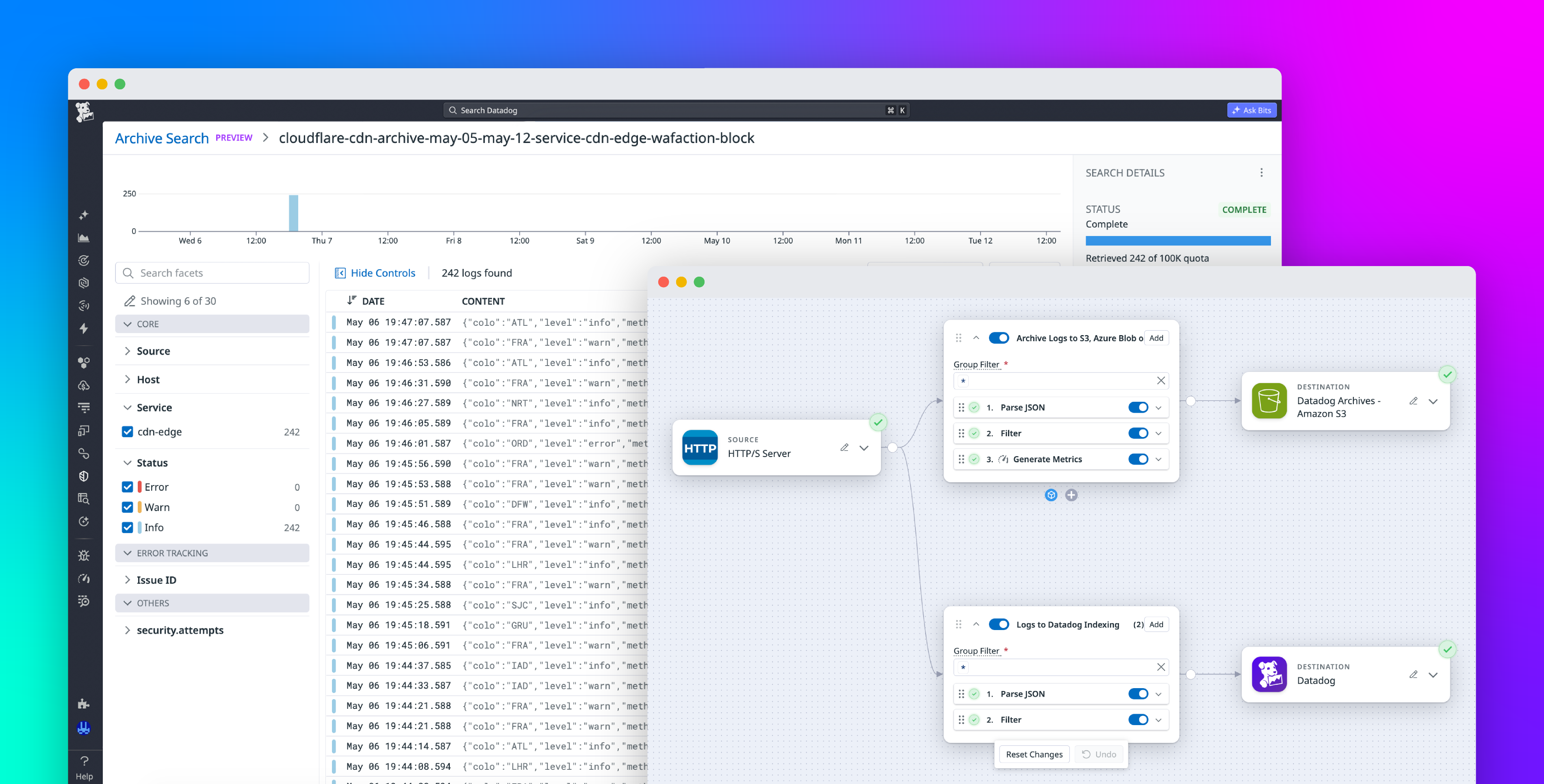
Datadog Observability Pipelines and Archive Search provide a cost-conscious pattern for retaining and investigating high-volume CDN logs. You can use Observability Pipelines to process and route raw edge logs to object storage while sending key metrics and high-signal events to Datadog for monitoring and alerting. When an investigation requires historical context, Archive Search lets you query archived logs from Datadog, helping teams keep CDN data accessible without indexing every event for long-term retention.