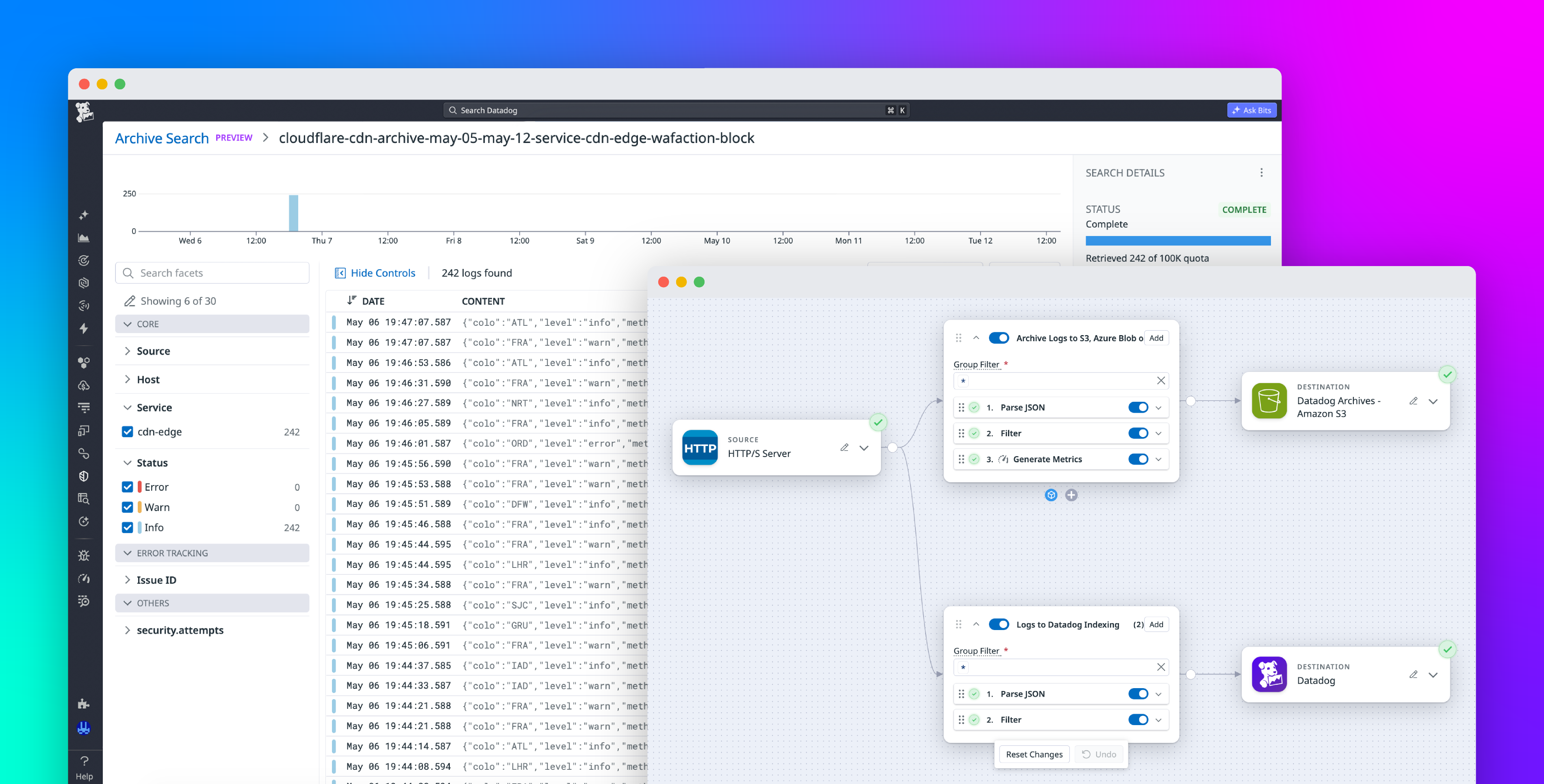
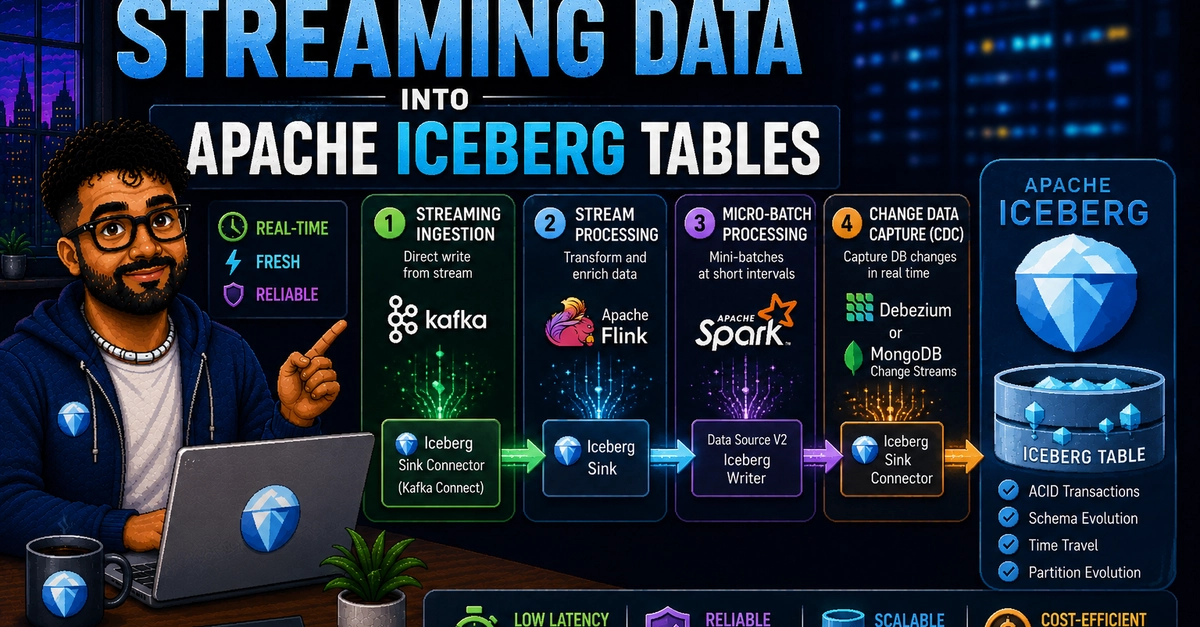
TL;DR — A Kafka + Flink + OTel ingestion pipeline cost us ~$700–800/month at 10 MB/s. We rebuilt it as a single binary where the data, the write-ahead log, and the Iceberg catalog all live in S3 alone — no Kafka, no local disks, no coordination service — for ~$100/month. Here's the design.
Self-hosted observability sooner or later runs into the problem of storing state. Query load, CPU, and data volume can all be handled by scaling out, but the stateful layer is something you have to operate by hand. At first it's almost unnoticeable: a disk degrades here, replication falls behind there, a recovery hangs somewhere else. As the data grows, incidents stop being one-offs and start to recur. At some point your observability stack - whether it's Grafana Loki, Elastic, or ClickHouse - starts demanding the same attention as a full-blown database that you're on the hook for.
Kubernetes operators cover some of these cases, but operating the state is still on you. Managed solutions take that burden away and bring their own: rising costs, ingestion-pipeline constraints, and limits on retention and cardinality.
But if you'd rather not sign up for the constant operational grind - or live with the constraints of managed solutions - it's worth asking: can we take the stateful part out of operations entirely?