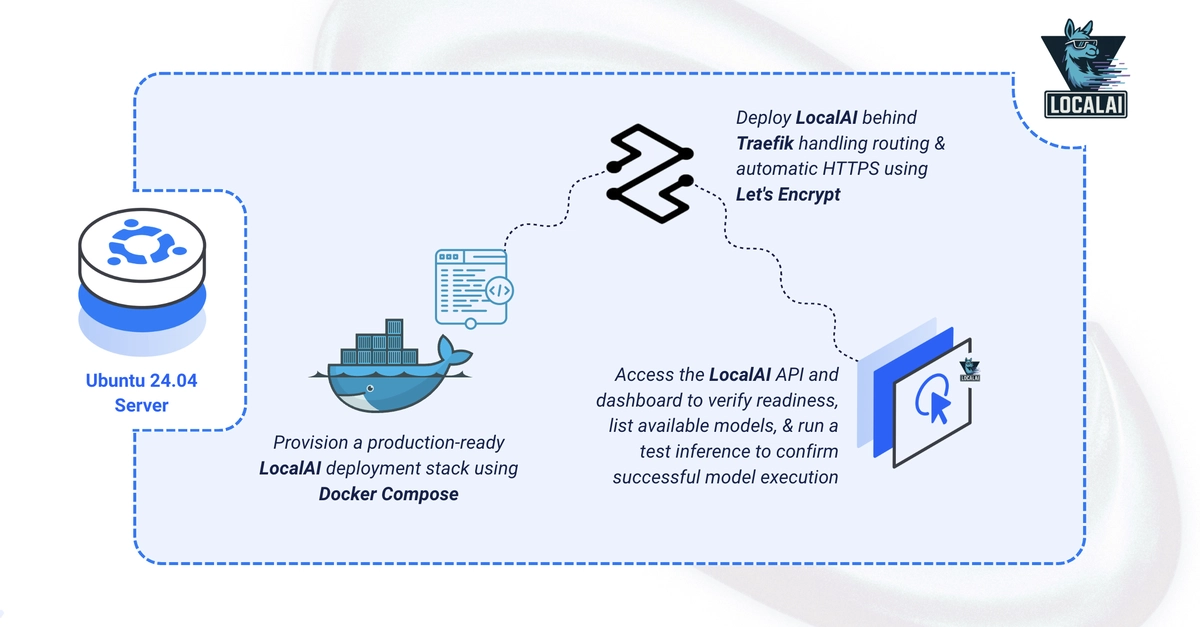
Back to Articles
Prerequisites Launch the server Query it from anywhere Clean up Going further: bigger models Going further: Chat with it in a UI Going further: SSH into the running server Going further: Use it as a coding-agent backend with Pi HF Jobs or Inference Endpoints? Further reading You can spin up a private, OpenAI-compatible LLM endpoint on Hugging Face infrastructure with a single command — no servers to provision, no Kubernetes, pay-per-second. Once it's up, you can query it from your laptop, a notebook, or anywhere else.
It's the quickest way to stand up a model for tests, evals, or batch generation. (If you're after a managed, production-ready service instead, that's what Inference Endpoints are for — more on when to pick which at the end.)
Here's the whole thing end to end.
Prerequisites