Introduction
Part 3 of the Zero Dollar personal AI Assistant series, running Local LLMs on a Free Cloud Server — What Actually Works. Part 1 covers the architecture. Part 2 covers free Oracle Cloud setup.
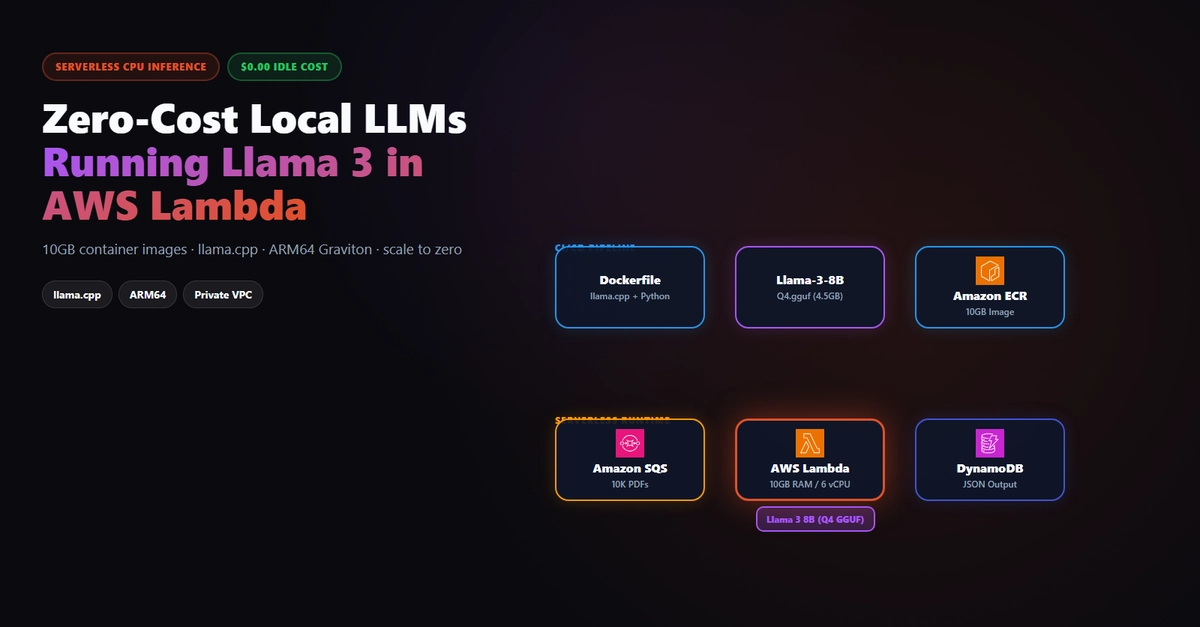
Running a language model locally sounds straightforward until you try it. Download a model, point your app at it, done. In practice, there are real constraints: RAM limits, disk-space surprises, and CPU inference-speed walls that most tutorials gloss over.
This article is honest about all of it. What works on a free Oracle ARM instance, what doesn't, and how a hybrid local + free API fallback makes the whole thing practical.
The CPU Inference Reality Check