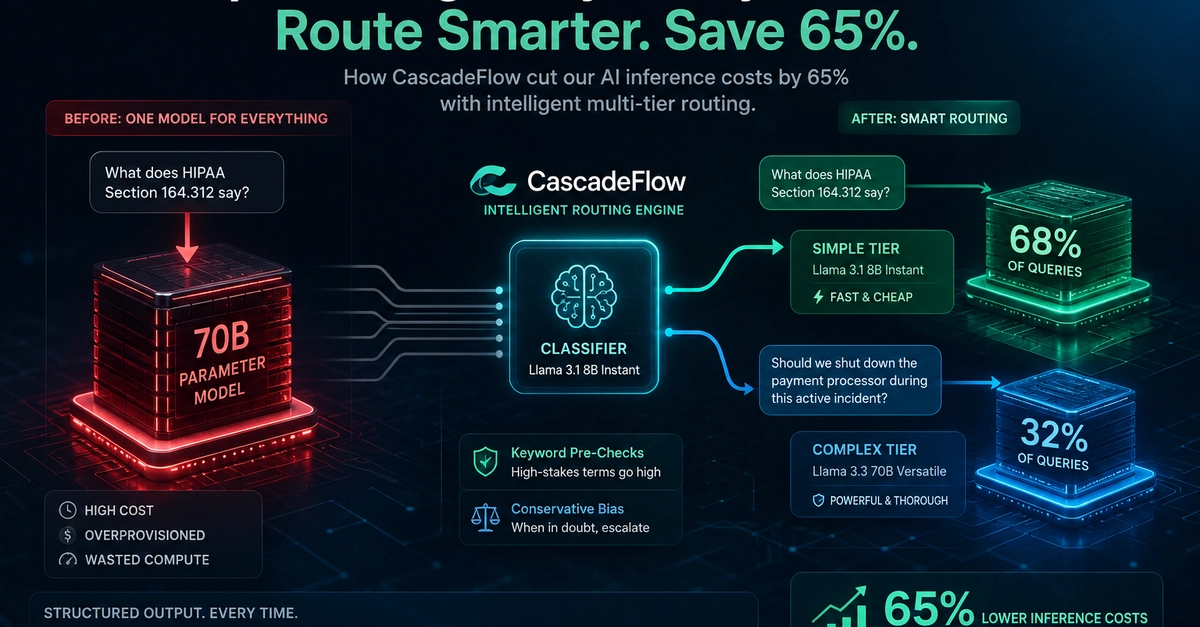
When the storage backend for Stream Router hit hard limits, we needed to redesign its data model and migrate it to a new storage architecture without disrupting live production traffic. We would not have completed the implementation in the time frame we had without AI tools.
We used Claude and Cursor to accelerate a systematic, test-driven refactoring process. They weren’t generating code autonomously: For each method, we provided the old implementation, the new schema, and a failing test. The models would generate a first pass, and the tests told us whether it was correct.
We were curious whether AI could help us safely evolve a critical production system. This post is about what worked, what didn’t, and what we learned along the way. We’ll walk through the migration itself, the workflow we used, what gave us confidence in the migration, and where the models were useful versus where they still required human expertise.
Before we get into the migration, it’s worth understanding the system we were changing.
At Datadog, we ingest massive volumes of metrics data every second as part of a platform that processes over a hundred trillion events per day. Routing that data correctly is just as important as ingesting it. Every datapoint then needs to be routed to the right Kafka cluster, topic, and set of partitions so it can be stored and queried correctly, and those routing decisions are constantly changing as our infrastructure evolves. (For a deeper look at the full metrics pipeline, see our overview of the metrics platform.)