Meta’s data ingestion system, which our engineering teams leverage for up-to-date snapshots of the social graph, has recently undergone a significant revamp to enhance its reliability at scale.
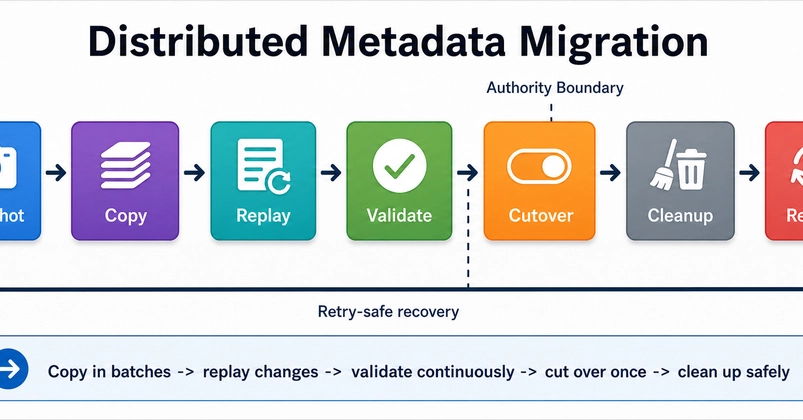
Moving from our legacy system to our new architecture required a large-scale migration of our entire data ingestion system.
We’re sharing the solutions and strategies that enabled a successful large-scale system migration, as well as the key factors that influenced our architectural decisions.
At Meta, our social graph is powered by one of the largest MySQL deployments in the world. Every day, our data ingestion system incrementally scrapes several petabytes of social graph data from MySQL into the data warehouse to power the analytics, reporting, and downstream data products that teams across the company utilize for tasks ranging from day-to-day decision-making to machine learning model training and product development.
We’ve recently revamped our data ingestion system’s architecture to significantly enhance its efficiency and reliability. The new architecture moves away from customer-owned pipelines, which functioned effectively at a small scale, to a simpler self-managed data warehouse service that still operates efficiently at hyperscale.