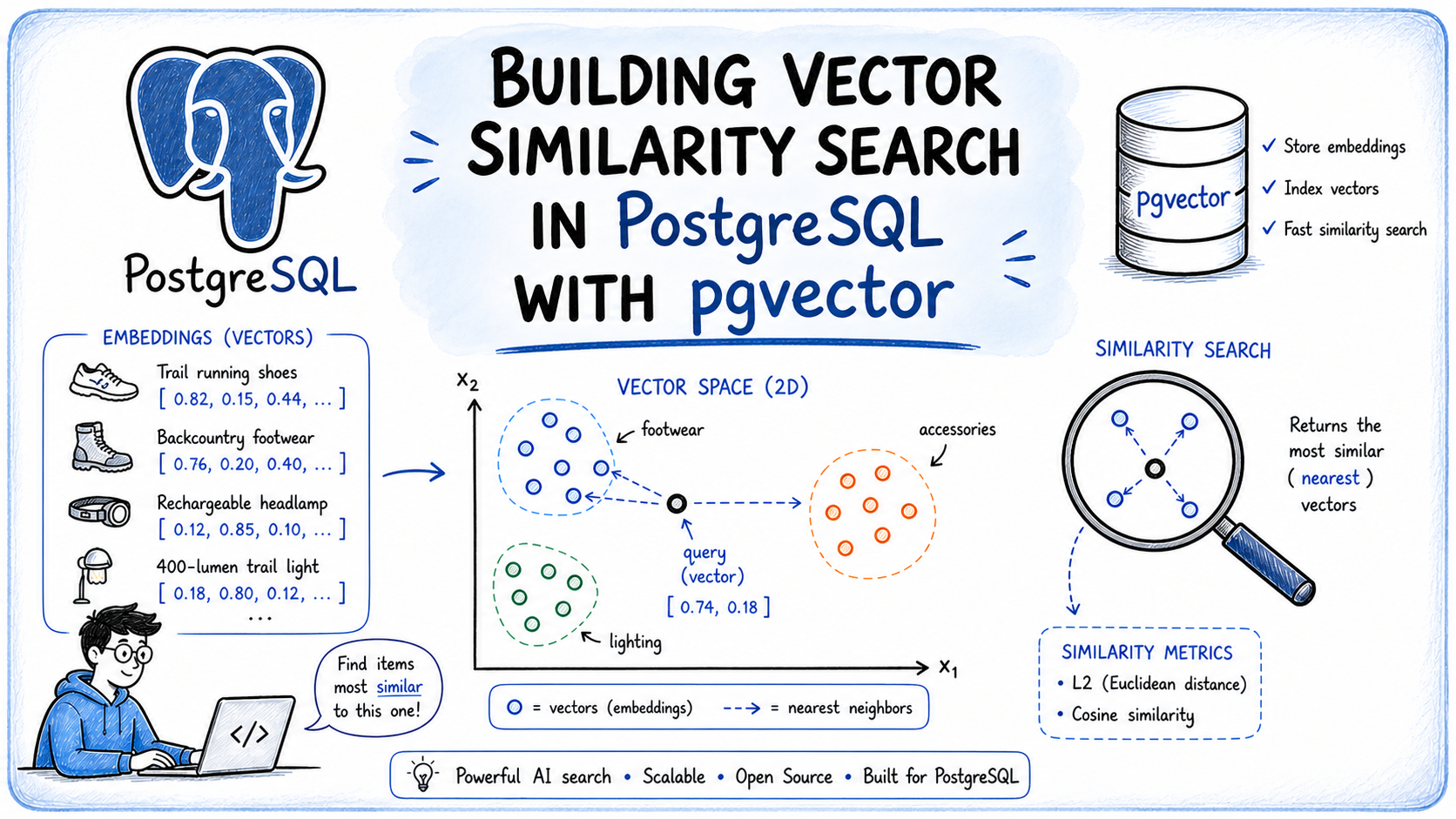
Embeddings turn meaning into vectors (last post). But if you have a million of them, how do you find the right ones for a query — fast? That's what a vector database does, and it's the retrieval engine behind every RAG app. Here's a live semantic search demo.
Search becomes "find the nearest vectors"
Embed your query into the same space as your documents, then find the document vectors closest to it (by cosine similarity). Because closeness = meaning, the query "how do I reset my password" matches a doc about "recovering account access" — even with zero shared keywords. The demo shows this beating a keyword search that returns nothing.
Why you need a database, not a for-loop
Comparing your query to every vector (brute-force kNN) is fine for hundreds, hopeless for millions. Vector DBs use ANN (approximate nearest neighbour) indexes like HNSW to find the closest vectors in milliseconds — trading a tiny bit of accuracy for huge speed.